[toc]
概述
版本号
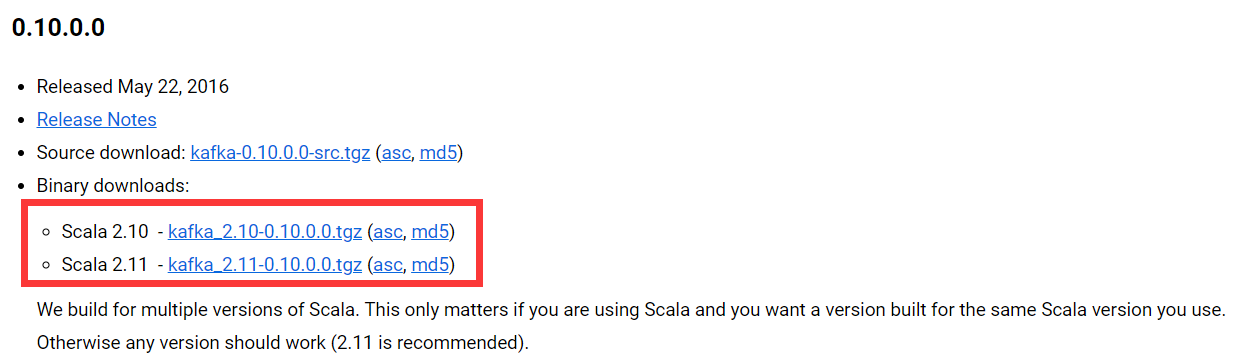
例如kafka_2.11-0.10.0.0,前面的2.11是编译Kafka源代码的Scala编译器版本,后面的0.10.0.0才是Kafka真正的版本号,1.0.0之后的版本命名规则从4位变成了3位,比如:kafka_2.11-2.1.1 [其中2代表大版本号,1表示小版本号或次版本号,1表示修订版本号]
版本演进
总共有7个大版本的演进: 0.7、0.8、0.9、0.10、0.11、1.0 和 2.0
0.7 版本 只提供了最基础的消息队列功能,无副本机制;
0.8版本 之后正式引入了副本机制,从而Kafka 成为了一个真正意义上完备的分布式高可靠消息队列解决方案 ;
0.9 大版本增加了基础的安全认证 / 权限功能,同时使用 Java 重写了新版本消费者 API,另外还引入了 Kafka Connect 组件用于实现高性能的数据抽取。
0.10.0.0 版本引入了 Kafka Streams,Kafka 正式升级成分布式流处理平台,但 Kafka Streams 还基本不能线上部署使用 ;
0.11.0.0 版本,引入了两个功能:一个是提供幂等性 Producer API 以及事务(Transaction) API;另一个是对 Kafka 消息格式做了重构;
- 0和2.0主要是对Kafka Streams的各种改进。
不论使用哪个版本,都尽量保持服务器端版本和客户端版本一致。
使用
配置文件
#server.properties
############################# Server Basics #############################
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=0
############################# Socket Server Settings #############################
listeners=PLAINTEXT://bigdata-pro01.bigDAta.com:9092
# The port the socket server listens on
port=9092
# Hostname the broker will bind to. If not set, the server will bind to all interfaces
host.name=bigdata-pro01.bigDAta.com
# The number of threads handling network requests
num.network.threads=3
# The number of threads doing disk I/O
num.io.threads=8
# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=102400
# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400
# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600
############################# Log Basics #############################
# A comma seperated list of directories under which to store log files
log.dirs=/opt/modules/kafka_2.10-0.9.0.0/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
log.cleaner.enable=false
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=bigdata-pro01.bigDAta.com:2181,bigdata-pro02.bigDAta.com:2181,bigdata-pro03.bigDAta.com:2181
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=6000
配置zookeeper. properties
#该目录需要与zookeeper集群配置保持一致
dataDir=/opt/modules/zookeeper-3.4.5-cdh5.10.0/zkData
# the port at which the clients will connect
clientPort=2181
# disable the per-ip limit on the number of connections since this is a non-production config
maxClientCnxns=0配置producer.properties
metadata.broker.list=bigdata-pro01.bigDAta.com:9092,bigdata-pro02.bigDAta.com:9092,bigdata-pro03.bigDAta.com:9092
producer.type=sync
compression.codec=none
# message encoder
serializer.class=kafka.serializer.DefaultEncoder
配置consumer.properties
zookeeper.connect=bigdata-pro01.bigDAta.com:2181,bigdata-pro02.bigDAta.com:2181,bigdata-pro03.bigDAta.com:2181
# timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=6000
#consumer group id
group.id=test-consumer-group编写Kafka Consumer执行脚本
#/bin/bash
echo "bigDAta-kafka-consumer.sh start ......"
bin/kafka-console-consumer.sh --zookeeper bigdata-pro01.bigDAta.com:2181,bigdata-pro02.bigDAta.com:2181,bigdata-pro03.bigDAta.com:2181 --from-beginning --topic weblogs启动命令
启动kafka之前一定要启动zookeeper。
$ bin/kafka-server-start.sh config/server.properties
$ bin/kafka-server-start.sh config/server.properties &常用命令
#创建名为weblogs的topic:
#partitions-topic分区数;控制topic将分片成多少个log。可以显示指定,如果不指定则会使用broker(server.properties)中的num.partitions配置的数量
#replication-factor-topic每个分区的副本数;控制消息保存在几个broker(服务器)上,一般情况下等于broker的个数。
#如果没有在创建时显示指定或通过API向一个不存在的topic生产消息时会使用broker(server.properties)中的default.replication.factor配置的数量
1.$ bin/kafka-topics.sh --zookeeper bigdata-pro01.bigDAta.com:2181,bigdata-pro02.bigDAta.com:2181,bigdata-pro03.bigDAta.com:2181 --create --topic weblogs --replication-factor 2 --partitions 1
#查看所有topic列表
2.$ bin/kafka-topics.sh --zookeeper bigdata-pro03.bigDAta.com:2181 --list
#查看指定topic信息
3.$ bin/kafka-topics.sh --zookeeper bigdata-pro03.bigDAta.com:2181 --describe --topic weblogs
#控制台向topic生产数据
4.$ bin/kafka-console-producer.sh --broker-list bigdata-pro01.bigDAta.com:2181,bigdata-pro02.bigDAta.com:2181,bigdata-pro03.bigDAta.com:2181 --topic weblogs
#控制台消费topic的数据
5.$ bin/kafka-console-consumer.sh --zookeeper bigdata-pro03.bigDAta.com:2181 --topic weblogs --from-beginning
#查看topic某分区偏移量最大(小)值 time为-1表示最大值,为-2时表示最小值
6.$ bin/kafka-run-class.sh kafka.tools.GetOffsetShell --topic weblogs --time -1 --broker-list bigdata-pro03.bigDAta.com:9092 --partitions 0
#增加topic分区数:这里增加10个分区
7.$ bin/kafka-topics.sh --zookeeper bigdata-pro03.bigDAta.com:2181 --alter --topic weblogs --partitions 10
#删除topic:删除topic的前提是broker的delete.topic.enable = true;否则删除topic的请求,只是通过zookeeper对topic进行标记为marked for deletion而没有真正的删除;
8.$ bin/kafka-topics.sh --zookeeper bigdata-pro03.bigDAta.com:2181/kafka-cluster --delete --topic weblogs
#如果上述命令无法正常删除topic,则需要对kafka在zookeeper中的存储信息进行删除
$ bin/zkCli.sh #进入zookeeper客户端
$ ls /brokers/topics #找到topic所在的目录
$ rmr /brokers/topics/topicName
#如何删除被标记了的topic
$ bin/zkCli.sh #进入zookeeper客户端
$ ls /admin/delete_topics #找到要删除的topic
$ rmr /admin/delete_topics/topicName #执行删除命令
出现的问题
FATAL Fatal error during KafkaServer startup. Prepare to shutdown (kafka.server.KafkaServer)
kafka.common.InconsistentBrokerIdException: Configured brokerId 0 doesn't match stored brokerId 1 in meta.properties
at kafka.server.KafkaServer.getBrokerId(KafkaServer.scala:630)
at kafka.server.KafkaServer.startup(KafkaServer.scala:175)
at kafka.server.KafkaServerStartable.startup(KafkaServerStartable.scala:37)
at kafka.Kafka$.main(Kafka.scala:67)
at kafka.Kafka.main(Kafka.scala)
原因:运行过Kafka之后,会产生meta.properties文件。修改config/server.properties文件的broker.id之后,与meta.properties文件值不同了,故产生错误。
解决:删除掉logs文件夹下的所有文件
org.apache.kafka.common.KafkaException: Failed to construct kafka producer
at org.apache.kafka.clients.producer.KafkaProducer.<init>(KafkaProducer.java:321)
at org.apache.kafka.clients.producer.KafkaProducer.<init>(KafkaProducer.java:181)
at kafka.producer.NewShinyProducer.<init>(BaseProducer.scala:36)
at kafka.tools.ConsoleProducer$.main(ConsoleProducer.scala:46)
at kafka.tools.ConsoleProducer.main(ConsoleProducer.scala)
Caused by: org.apache.kafka.common.config.ConfigException: DNS resolution failed for url in bootstrap.servers: bigdata-pro01.bigDAta.com:9092
at org.apache.kafka.clients.ClientUtils.parseAndValidateAddresses(ClientUtils.java:49)
at org.apache.kafka.clients.producer.KafkaProducer.<init>(KafkaProducer.java:269)
... 4 more
org.apache.kafka.common.KafkaException: Failed to construct kafka producer
at org.apache.kafka.clients.producer.KafkaProducer.(KafkaProducer.java:321)
at org.apache.kafka.clients.producer.KafkaProducer.(KafkaProducer.java:181)
at kafka.producer.NewShinyProducer.(BaseProducer.scala:36)
at kafka.tools.ConsoleProducer$.main(ConsoleProducer.scala:46)
at kafka.tools.ConsoleProducer.main(ConsoleProducer.scala)
Caused by: org.apache.kafka.common.config.ConfigException: DNS resolution failed for url in bootstrap.servers: bigdata-pro01.bigDAta.com:9092
at org.apache.kafka.clients.ClientUtils.parseAndValidateAddresses(ClientUtils.java:49)
at org.apache.kafka.clients.producer.KafkaProducer.(KafkaProducer.java:269)
#版本不一致导致的问题,
Error reading field 'brokers': Error reading field 'host': Error reading string of length 25193, only 115 bytes available##The isue is in the offsets.topic.replication.factor & replication.factor configs.
Discovered coordinator bigdata-pro01.bigDAta.com:9092 (id: 2147483647 rack: null) for group spark-kafka-source-af454461-ef0d-4f50-998b-7c672e7c2c9f-855341412-executor.
20/04/24 20:59:30 ERROR Executor: Exception in task 0.0 in stage 2.0 (TID 201)


