[toc]
概述
学习网站:
https://databricks.com/spark/about —-关注其中的Blog
Apache Spark™是用于大规模数据处理的统一分析引擎。Spark也是基于map、reduce算法模式实现的分布式计算框架,拥有Hadoop MapReduce所具有的优点,并解决了Hadoop MapReduce中的诸多缺陷;
下载
官网-download。
将Spark源码下载并解压
编译
- 编译方式
- Maven编译
- SBT编译
- 打包编译make-distribution.sh
选择Maven方式编译。

spark的编译对maven,java版本有要求,下载并解压相应版本的Maven和Java。
(a)
#配置JAVA_HOME
$ sudo vi /etc/profile
export JAVA_HOME=/XXX/XXX/jdkX.X.X_XX
export PATH=$PATH:$JAVA_HOME/bin编辑退出后,使用source /etc/profile使之生效;
#如果遇到不能加载当前版本的问题
rpm -qa|grep jdk
rpm -e --nodeps jdk版本
which java 删除/usr/bin/java(b)
$ sudo vi /etc/profile
export MAVEN_HOME=
export PATH=$PATH:$MAVEN_HOME/bin
#configure Maven to use more memory than usual by setting MAVEN_OPTS
export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=1024M -XX:ReservedCodeCacheSize=1024M" PS:
<!--ReservedCodeCacheSize是可选的,但是不写的话可能会出错-->
[INFO] Compiling 203 Scala sources and 9 Java sources to /Users/me/Development/spark/core/target/scala-2.12/classes...
[ERROR] Java heap space -> [Help 1]编辑退出后,使用source /eytc/profile使之生效;
#/etc/resolv.conf:添加如下内容
nameserver 8.8.8.8
nameserver 8.8.4.4
#spark/dev/make-distribution.sh
#Spark的版本
VERSION=
#Scala的版本
SCALA_VERSION=
#Hadoop的版本
SPARK_HADOOP_VERSION=
#支持spark on hive
SPARK_HIVE=1
#加快编译速度#编译时网络要外网连接
$./dev/make-distribution.sh --name custom-spark --tgz -Phadoop-X.X -Phive -Phive-thriftserver -Pyarn
#编译完成之后解压
tar -zxf spark-X.X.X-bin-custom-spark.tgz -C /opt/modules/Scala安装
官网中描述对于Sacla的版本也是有要求的,将相应版本的Scala下载解压到指定目录。
配置环境变量
$ sudo vi /etc/profile
export SCALA_HOME=/XXX/XXX/scala-X.XX.X
export PATH=$PATH:$SCALA_HOME/bin
$ source /etc/profile运行
Spark运行模式:
Local(运行在一台机器上,通常用于练手或者测试环境)
将网络切换至内网,进入Spark安装目录,执行
./bin/spark-shellStandalone(构建一个基于Master+Slaves的资源调度集群,Spark任务提交给Master运行,是Spark自身的集群管理)
需要安装JDK、Scala、Hadoop、Spark Standalone(只需要在集群中每个节点上安装一个Spark的编译版本)
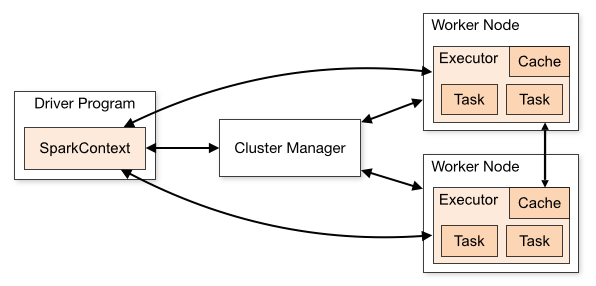
$./sbin/start-master.sh:启动一个standalone master服务,一旦启动,master将打印spark://HOST:PORTURL,这个URL可以连接workers,或者作为”master”参数传递给SparkContext,也可以在master’s的web UI中发现这个URL。$./sbin/start-slave.sh <master-spark-URL>:启动workers,并连接master。使用脚本启动Spark standalone 集群,需要在Spark目录下创建conf/slaves文件,并在文件中写入计划运行Spark workers机器的hostname,如果该文件不存在,默认启动Local模式。注意:master机器可以无密钥连接每一个worker。
#slaves:一行一个 worker1 所在的hotname worker2 所在的hotname那么可以在
Spark master上运行以下脚本:#Starts a master instance on the machine the script is executed on. $ sbin/start-master.sh #Starts a slave instance on each machine specified in the conf/slaves file. $ sbin/start-slaves.sh #Starts a slave instance on the machine the script is executed on. $ sbin/start-slave.sh #Starts both a master and a number of slaves as described above. $ sbin/start-all.sh #Stops the master that was started via the sbin/start-master.sh script. $ sbin/stop-master.sh #Stops all slave instances on the machines specified in the conf/slaves file. $ sbin/stop-slaves.sh #Stops both the master and the slaves as described above $ sbin/stop-all.sh通过
conf/spark-env.sh进一步配置集群,可以参考conf/spark-env.sh.template,然后将该文件复制到所有worker机器上。#spark-env.sh export JAVA_HOME=/XXX/XXX/jdkX.X.X_XX export SCALA_HOME=/XXX/XXX/scala-X.XX.X #配置这一项时,hadoop集群得启动 export HADOOP_CONF_DIR=/opt/modules/hadoop-X.X.X/etc/hadoop export SPARK_CONF_DIR=/opt/modules/spark-X.X.X/conf #绑定master,填写hostname or IP address export SPARK_MASTER_HOST= #默认是7077 export SPARK_MASTER_PORT=7077 #master web UI的端口,默认是8080 export SPARK_MASTER_WEBUI_PORT=8080 #允许Spark 程序使用的内核总数 export SPARK_WORKER_CORES=1 #saprk程序使用的内存总数 export SPARK_WORKER_MEMORY=1g #Spark worker启动的端口,默认random export SPARK_WORKER_PORT=7078 #worker web UI的端口8081 export SPARK_WORKER_WEBUI_PORT=8081将应用程序连接到集群,只需要将master的URL(spark://IP:PORT)传递给SparkContext构造器。运行一个交互Spark shell:
$./bin/saprk-shell --master spark://IP:ROOT。spark-submit脚本提交编译的Spark应用程序到集群中。对于standalone集群,Spark有两种deploy modes:1.client( the driver is launched in the same process as the client that submits the application )2.cluster( the driver is launched from one of the Worker processes inside the cluster, and the client process exits as soon as it fulfills its responsibility of submitting the application without waiting for the application to finish )。如果你的应用程序通过Spark submit运行,则应用程序自动分发给所有的worker节点,应用程序所依赖的jar包,通过–jars jar1,jar2YARN(Spark客户端直接连接Yarn,不需要额外构建Spark集群)
确保HADOOP_CONF_DIR或者YARN_CONF_DIR指向包含Hadoop集群客户端配置文件的目录。这些配置用于向HDFS执行写操作合连接YARN ResourceManager。
在YARN上运行Spark应用程序有两种deploy mode:
- cluster mode:
- client mode:
Mesos(Spark初期支持)
运行的基本流程
启动:用户程序
启动SparkContext,是程序的总入口,初始化DAGScheduler作业调度和TaskScheduler任务调度;生成作业:DAGScheduler根据
shuffleDependency(宽依赖)将作业分为不同的stage,根据RDD之间的依赖关系[宽依赖、窄依赖],划分原则是遇到窄依赖就放进当前stage,遇到宽依赖则断开。相当于shuffleDependency是前后stage分界线,每一个stage里面都会划分一个taskset,也就是任务集,而DAGScheduler的下一个任务是将这个taskset传给TaskScheduler(在最后一个stage划分结束,就会触发作业的提交)提交任务集:TaskScheduler调用TaskSetManager
分配Task到哪一个executor上去执行,SchedulerBackend配合TaskScheduler完成具体任务的资源分配任务执行:Executor执行实际任务的运行,对每个task创建一个TaskRunner类,交给线程池去运行
状态的监控:主要是TaskScheduler通过一些回调函数通知DAGScheduler具体Executor的生命状态;
任务结果的获取:对于FinalStage
[直接触发作业的RDD(执行action算子的)关联的stage]的返回运算结果的本身,对于其他stage,返回给DAGScheduler是一个MapStaus,维护中间输出结果和block地址、存储位置信息将会作为下一阶段的任务的输入数据的依据。
Spark Core
RDD(resilient dastributed dataset)
2大创建:
Parallelized Collections
将已经存在的数据集转化成rdd/其他RDD转化形成新的RDD,一般在进行测试的时候使用
#sc即SparkContext val data = Array(1,2,3,4,5) #第二个参数10是手动创建的partitions,可选参数 val rdd = sc.parallelize(data,10)External Datasets
由外部存储系统的数据集创建,包括本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、HBase。
#URI(Uniform Resource Identifier,统一资源标识符),而URL(URL:Uniform Resource Location统一资源定位符),URL是URI的子集 #参数是文件的URI(file///,还可以是hdfs://,) val distFile = sc.textFile("data.txt") distFile: org.apache.spark.rdd.RDD[String] = data.txt MapPartitionsRDD[10] at textFile at:26
5大特性
<!--源码中的描述-->
* - A list of partitions
* - A function for computing each split
* - A list of dependencies on other RDDs
* - Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
* - Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
一组分片(Partition),即数据集的基本组成单位。 对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD 的时候指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Cores 的数目;
对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果;
RDD 之间互相存在依赖关系。 RDD 的每次转换都会生成一个新的 RDD ,所以 RDD 之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark 可以通过这个依赖关系重新计算丢失部分的分区数据,而不是对 RDD 的所有分区进行重新计算。—具有容错性
一个Partitioner ,即 RDD 的分片函数 。当前Spark 中实现了两种类型的分片函数,一个是基于哈希的 HashPartitioner ,另外一个是基于范围的 RangePartitioner。只有对于key-value的RDD ,才会有 Partitioner,非 key-value 的RDD 的 Partitioner 的值是None。Partitioner 函数不但决定了RDD 本身的分片数量,也决定了 Parent RDD Shuffle 输出时的分片数量。
一个列表,存储存取每个Partition 的优先位置(preferred location)。 对于一个HDFS 文件来说,这个列表保存的就是每个 Partition 所在的块位置。根据“移动数据不如移动计算”的理念,Spark 在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
3大操作方式(算子):
transformations:数据内容不会变化,形式改变,懒加载,只有在actions阶段才执行。
- 主要对数据进行切分、封装、转换、聚合、排序等操作;
- 每次操作都会创建新的RDD;
- 操作都是lazy级别的,需要action算子触发Job后真正执行;
- 主要分为普通算子和shuffle算子
| 操作 | 含义 |
|---|---|
| map(func) | 返回一个新的RDD,该RDD由每一个输入元素经func函数转换后组成 |
| filter(func) | 返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成 |
| flatMap(func) | 类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素) |
| repartition(numPartitions) | 重新分区 |
| join(otherDataset, [numTasks]) | 在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD 相当于内连接(求交集) |
| sample(withReplacement, fraction, seed) | 根据fraction指定的比例对数据进行采样,可以选择是否使用随机数进行替换,seed用于指定随机数生成器种子 |
| union(otherDataset) | 对源RDD和参数RDD求并集后返回一个新的RDD |
| intersection(otherDataset) | 对源RDD和参数RDD求交集后返回一个新的RDD |
| distinct([numTasks])) | 对源RDD进行去重后返回一个新的RDD |
| groupByKey([numTasks]) | 在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD |
| reduceByKey(func, [numTasks]) | 在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,与groupByKey类似,reduce任务的个数可以通过第二个可选的参数来设置 |
| sortByKey([ascending], [numTasks]) | 在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD |
| sortBy(func,[ascending], [numTasks]) | 与sortByKey类似,但是更灵活 第一个参数是根据什么排序 第二个是怎么排序 false倒序 第三个排序后分区数 默认与原RDD一样 |
| cogroup(otherDataset, [numTasks]) | 在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable |
map和flatMap的区别:
- map算子对RDD中每个元素进行函数转换操作,形成新的RDD,
新的RDD中数据与旧RDD中的数据是一一对应关系; - flatMap算子对RDD中每个元素进行函数转化操作,然后再
扁平化将所有的对象合并成新的RDD,新的RDD中数据与旧RDD中的数据是一对多对应关系;
两个算子都不会产生shuffle操作,都是窄依赖算子。
reduceByKey和groupByKey的区别:
- reduceByKey会在
结果发送至reduce之前对每个mapper在本地进行merge,这样有减少数据量传输,节省网络资源,并且能够保证reduce端能够很快的进行计算结果; - groupByKey会对
每一个RDD的value值进行聚合形成一个序列,并且该操作发生在reduce端,所以数据通过网络传输会浪费资源,如果数据量十分大,可能会造成OOM异常;groupByKey聚合后的序列是无序的。
actions:
- 可以称为输出算子,其主要作用将
RDD中的数据持久化到外部存储设备或Driver端; - Action算子会触发Job,并且是立即执行;
- 可以有返回值,其返回值是Scala中集合对象,将数据返回到Driver端
| 操作 | 含义 |
|---|---|
| reduce(func) | 通过func函数聚集RDD中的所有元素,这个功能必须是可交换且可并联的 |
| collect() | 以数组的形式返回数据集的所有元素 |
| count() | 返回RDD的元素个数 |
| first() | 返回RDD的第一个元素 |
| take(n) | 返回一个由数据集的前n个元素组成的数组 |
| saveAsTextFile(path) | 将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本 |
| countByKey() | 针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数 |
| foreach(func) | 在数据集的每一个元素上,运行函数func进行更新 |
| lookup | 对<key,value>型的rdd操作,返回指定key对应的元素形成的seq。如果这个rdd包含分区器,那么只扫描对应key所在的分区,若不含,则进行全盘扫描 |
controller:
| 操作 | 含义 |
|---|---|
| cache | 只有一个默认的缓存级别MeMORY-ONLY,cache调用了persist |
| persist | 可以根据情况设置其缓存级别 |
| 用处: | 两者都是用来将一个RDD进行缓存的,避免重复计算,从而节省程序运行的时间。 |
RDD的容错机制
利用
血缘(Lineage)容错:利用
依赖关系进行数据恢复,在容错机制中,如果一个节点死机了,而且运算
窄依赖,则只把丢失的父RDD分区重算即可,不依赖于其他节点;在窄依赖中,在子RDD的分区丢失,重算父RDD分区时,父RDD相应分区计算所得的数据都是子RDD的数据,并不存在冗余计算。
而
宽依赖需要父RDD的所有分区都存在,重算花销大;在宽依赖的情况下,丢失一个子RDD分区重算的
每个父RDD的每个分区的所有数据并不是都给子RDD分区用的,会有一部分数据相当于对应的是未丢失的子RDD分区中需要的数据,所以存在冗余计算 开销
检查点机制:
在宽依赖中,如果Lineage过长,重算开销会很大,通过设置
检查点,在依赖关系汇总,对关系中间预算的结果进行数据冗余备份,所以数据恢复时,就可以从检查点开始进行重新计算Lineage,减少开销
Spark SQL
DataFrame
DataFrame是Spark 1.3添加的接口,类似于传统数据库的二维表格或者 R 和 Python 中的一个 data frame,除了数据之外,还记录数据的结构信息,即schema;与Hive类似,DataFrame也支持嵌套数据类型(struct、array、map) DataFrame 是按命名列方式组织的一个 Dataset。DataFrame 可以从很多数据源构造得到,比如:结构化的数据文件,Hive 表,外部数据库或现有的 RDD。
val df = spark.read.json("examples/src/main/resources/people.json")DataSet
Dataset 是一个分布式数据集,它是 Spark 1.6 版本中新增的一个接口, 它结合了 RDD(强类型,可以使用强大的 lambda 表达式函数) 和 Spark SQL 的优化执行引擎的好处。Dataset 可以从 JVM 对象构造得到,可以使用函数式的变换(map,flatMap,filter 等) 进行操作 。
case class Person(name: String, age: Long)
val caseClassDS = Seq(Person("Andy", 32)).toDS()RDD、DataFrame、DataSet三者之间的异同
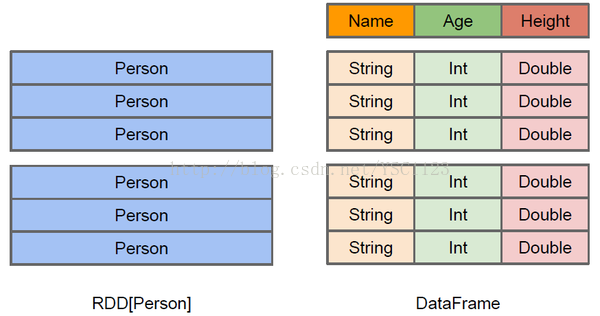
RDD中以对象为类型参数,Spark框架并不了解内部结构;而DataFrame提供了详细的结构信息,Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型。RDD是分布式的Java对象的集合,DataFrame也叫做DataSet[Row],是分布式的Row对象的集合。
如果同样的数据都给这三种数据集,他们分别计算之后,会给出相同的结果,但是执行效率和方式有所不同。
针对数据查询应用,在RDD之上,封装了DataFrame
三种join方式
为什么要进行整合?
hive原生是基于MapReduce的,导致其查询耗时较长。
为了保留Hive的架构解决方案,并优化查询速度,采用SparkSql与hive整合(spark on hive),通过SparkSql读取hive中表的元数据,把HiveHQL底层采用MapReduce处理任务导致性能慢的特点,改为更加强大的Spark引擎来进行相应的计算处理。
Spark-shell
需要的配置(spark集群)
1.拷贝Hive的配置文件Hive-site.xml,core-site.xml,HDFS的配置文件 hdfs-site.xml到Spark的conf目录;
2.拷贝hive中的mysql jar包到spark的jars目录;
3.检查spark-env.sh文件中hadoop的配置项;
export HADOOP_CONF_DIR=/opt/modules/hadoop-2.6.0/etc/hadoop
需要启动的服务
1.sudo service mysqld start
2.bin/hive –service metastore
Spark-sql
不需要配置,spark-shell能运行,这个也可以运行。
beeline:
与HBase集成
其核心就是Spark SQL通过Hive外部表来获取HBase的表数据
拷贝Hbase的包和Hive的包放到Spark的jars目录下:
#hbase安装目录下
hbase-client-x.x.x.jar
hbase-common-x.x.x.jar
hbase-protocol-x.x.x.jar
hbase-server-x.x.x.jar
#hive安装目录下
hive-hbase-handler-x.x.x.jar
htrace-core-x.x.jar
mysql-connector-java-x.x.x-bin.jarSpark Streaming
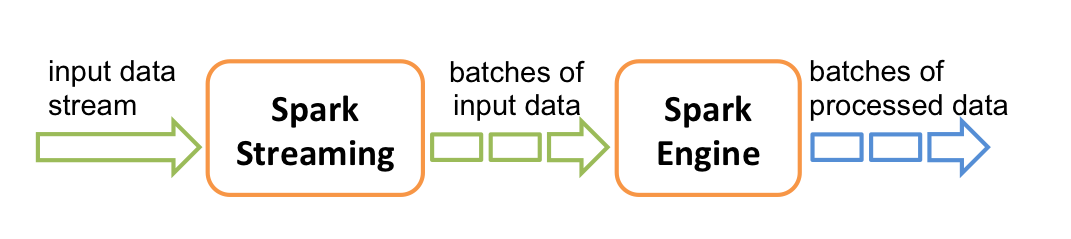
Spark Streaming 是对Spark 核心API 的一个扩展,它能够实现对实时数据流的流式处理,并具有很好的可扩展性、高吞吐量和容错性。Spark Streaming 支持从多种数据源提取数据,如:Kafka、Flume、Twitter、ZeroMQ、Kinesis 以及 TCP 套接字,并且可以提供一些高级 API 来表达复杂的处理算法,如:map、reduce、join 和 window 等。最后,Spark Streaming 支持将处理完的数据推送到文件系统、数据库或者 live dashboards 中展示 。 还可以将 Spark 的机器学习(machine learning) 和 图计算(graph processing)的算法应用于Spark Streaming 的数据流当中 。

工作原理
Spark Streaming 接收实时输入数据流并根据自定义的时间间隔将数据划分为一个个小的批次供 Spark Engine (其实是Spark Core)处理,最终生成多个批次的结果流( 而Storm是来一条数据处理一条数据,是真正意义上的实时处理)。 其底层操作还是基于RDD的,只不过针对实时计算的特点,在RDD之上封装了DStream[离散数据流](被分成的一段段的数据)。每一段数据都可以转换成RDD,从而将对DStream的操作变成了对RDD的操作,RDD经过操作之后变成中间结果保存在内存中,也可以根据业务需求对中间结果进行缓存/存储到外部设备。
性能调优手段
反压机制
Structured Streaming
出现的原因:
- 以RDD为核心的API逐步升级到DataSet/DataFrame上;
- 以RDD为基础的编程模型对开发人员的要求较高,需要足够的编程背景才能够胜任Spark Streaming的编程工作
Structured Streaming是一种基于Spark SQL引擎的可扩展且容错的流处理引擎。可以像表达静态数据的批处理计算一样表达流式计算。Spark SQL引擎将负责逐步和连续地运行它,并在流数据继续到达时更新最终结果。可以使用Scala,Java,Python或R中的数据集/数据框架API来表示流聚合,事件时间窗口,流到批处理连接等。计算在同一优化的Spark SQL引擎上执行。最后,系统通过检查点和预写日志确保端到端的一次性容错保证。简而言之,结构化流传输提供快速,可扩展,容错,端到端的精确一次流处理,而无需用户推理流式传输。
Structured Streaming 将数据源和计算结果都看做是无限大的表,数据源中每个批次的数据,经过计算,都添加到结果表中作为行。
借助官网的例子理解一下Structured Streaming的运作方式,每次流入的数据会作为一行新数据添加到Unbounded Table上,同时将流式计算的结果映射为另外一张表,完全以结构化的方式操作流式数据。
输出模式:
update: 输出只有自上次触发后在结果表中更新的行;
append : 输出自上次触发后,结果表中附加的新行。这仅适用于预计结果表中的现有行不会更改的查询 ;
complete: 输出整个更新的结果表。
Spark 解决数据倾斜
数据倾斜
什么是数据倾斜
数据倾斜指的是,
并行处理的数据集中,某一部分的数据显著多于其它部分,从而使得该部分的处理速度成为整个数据集处理的瓶颈。数据倾斜的现象
绝大多数task执行得都非常快,但个别task执行极慢;这种情况常见
原本能够正常执行的spark作业,某天突然爆出OOM(内存溢出)异常,观察异常栈,是业务代码造成的;这种情况比较少见
数据倾斜发生的本质原因
在进行
shuffle的时候,必须将各个节点上相同的key拉取到某一个节点上的task来进行处理,比如按照key进行聚合或join等操作。此时如果每个key对应的数据量特别大的话,就会出现数据倾斜。整个Spark作业的运行进度是由运行时间最长的那个task决定的;哪些算子会导致数据倾斜
数据倾斜
只会发生在shuffle过程中,可能会触发shuffle操作的算子:distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition等首先,
确定数据倾斜发生在第几个stage,无论是yarn-client,还是yarn-cluster模式提交,都可以通过Spark Web UI上查看当前这个stage各个task分配的数据量;其次,根据stage划分原理,推算出发生倾斜的那个stage对应代码中的哪一部分,找能发生shuffle的算子
常见解决方案
使用Hive ETL 预处理数据
过滤少数导致倾斜的key
提高shuffle操作的并行度
两阶段聚合(局部聚合+全局聚合)
将原本相同的key通过附加随机前缀的方式,变成多个不同的key,就可以让原本被一个task处理的数据分散到多个task上去做局部聚合,进而解决单个task处理数据量过多的问题;接着去掉随机前缀,再次进行全局聚合,就可以得到最终的结果
将reduce join转为map join
采用倾斜key并分拆join操作
使用随机前缀和扩容RDD进行join
使用IntelliJ IDEA构建Maven管理的Spark项目
Maven安装与配置
参考文献: https://how2j.cn/k/idea/idea-maven-config/1353.html#nowhere
打开官网:http://maven.apache.org/download.cgi,在`Previous Releases处点击archives进入版本下载页面。下载并解压,配置环境变量新增M2_HOME,并修改Path,cmd窗口执行mvn -v`看到maven的当前版本即配置成功。
修改maven/conf/settings.xml
<!-- localRepository
| The path to the local repository maven will use to store artifacts.
|
| Default: ${user.home}/.m2/repository
<localRepository>/path/maven/repo</localRepository>
-->
将注释去掉,将 <localRepository></localRepository>修改为自定义repository的路径。打开idea,进行maven配置:File-Settings-Build,Execution,Deployment-Build Tools-Maven修改’Maven home directory’、’User settings file’、’Local repository’,点击’apply’-‘ok’按钮结束。
Scala for windows下载
确保本地已安装JDK1.5以上版本,并设置了JAVA_HOME环境变量及JDK的bin目录。
主要分为以下几个步骤(参考文献: https://blog.csdn.net/zkf541076398/article/details/79297820 ):
安装Scala 插件
a.可以在idea中直接通过File->Settings->Plugins安装(没有安装成功,可能是网慢);
b.也可以去官网( https://plugins.jetbrains.com/plugin/1347-scala/versions )下载对应的版本(!!!!!一定要在idea中确定所需插件的版本),将下载的.zip文件放在idea的plugins目录下,或者其他目录下,通过
Install plugin from disk...进行安装。记得重启idea,使插件生效。JDK和Sacla SDK
为了不用每个项目都配置JDK和Library,从而进行全局配置
File-Other Settings-Default Project Structure在project页面配置JDK,在Global Libraries页面添加Scala SDK新建maven项目
打开新建好项目的Project Structure窗口,将Scala SDK添加到Libraries下,注意新建Scala文件时,应该选择
Object,而不是class,否则没有run按钮,为什么不会出现呢????点击运行按钮之后出现
java.io.IOException: Could not locate executable D:\xuling\ideaWorkSpce\bigData_software\hadoop-2.6.0\bin\winutils.exe in the Hadoop binaries.该bin文件内缺少winutils.exe,用以2.6.4目录下的下文件代替即可
导入spark依赖
修改pom.xml,可以参考( https://github.com/apache/spark/blob/master/examples/pom.xml )例子
编写spark代码
打包在spark上运行



