[toc]
项目简介
项目目标
- 完成大数据项目的架构设计,安装部署,架构继承与开发,用户可视化交互设计
- 完成实时在线数据分析
- 完成离线数据分析
具体功能
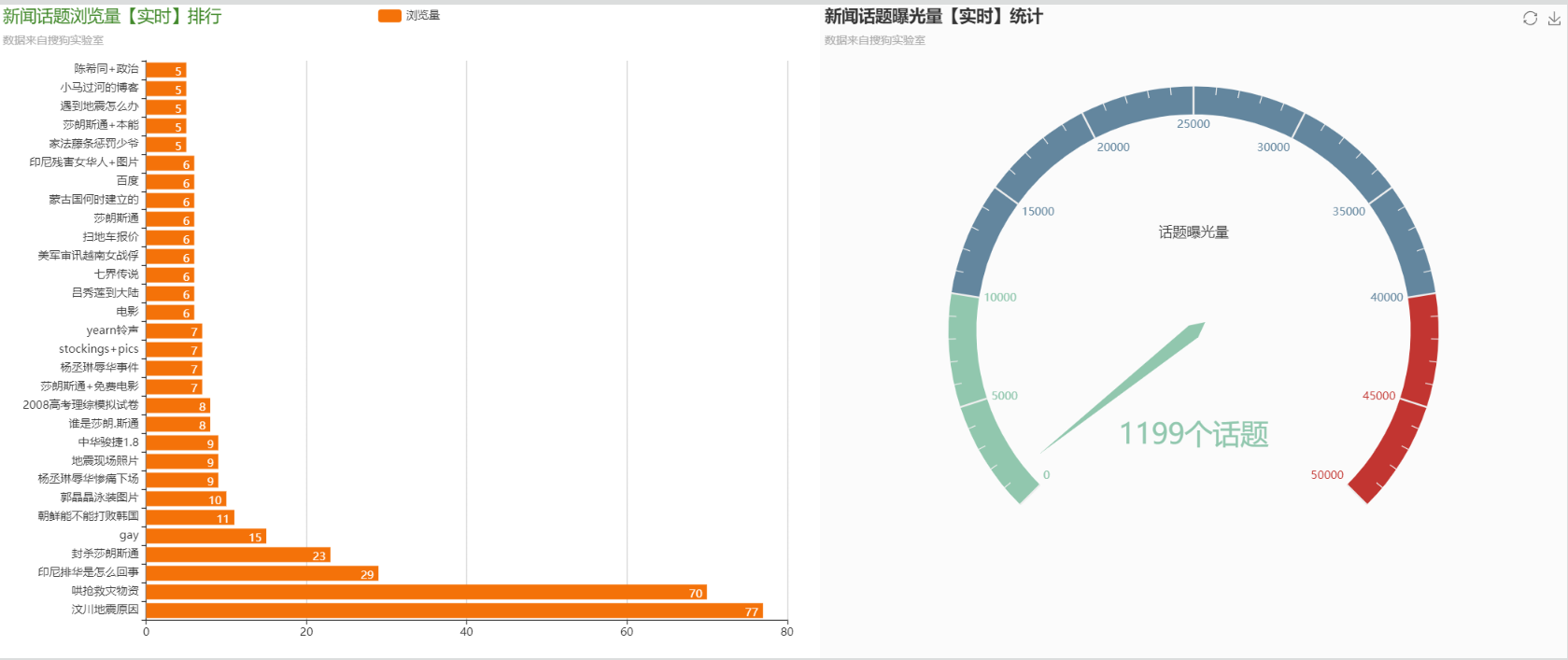
- 捕获用户浏览日志信息(TB)
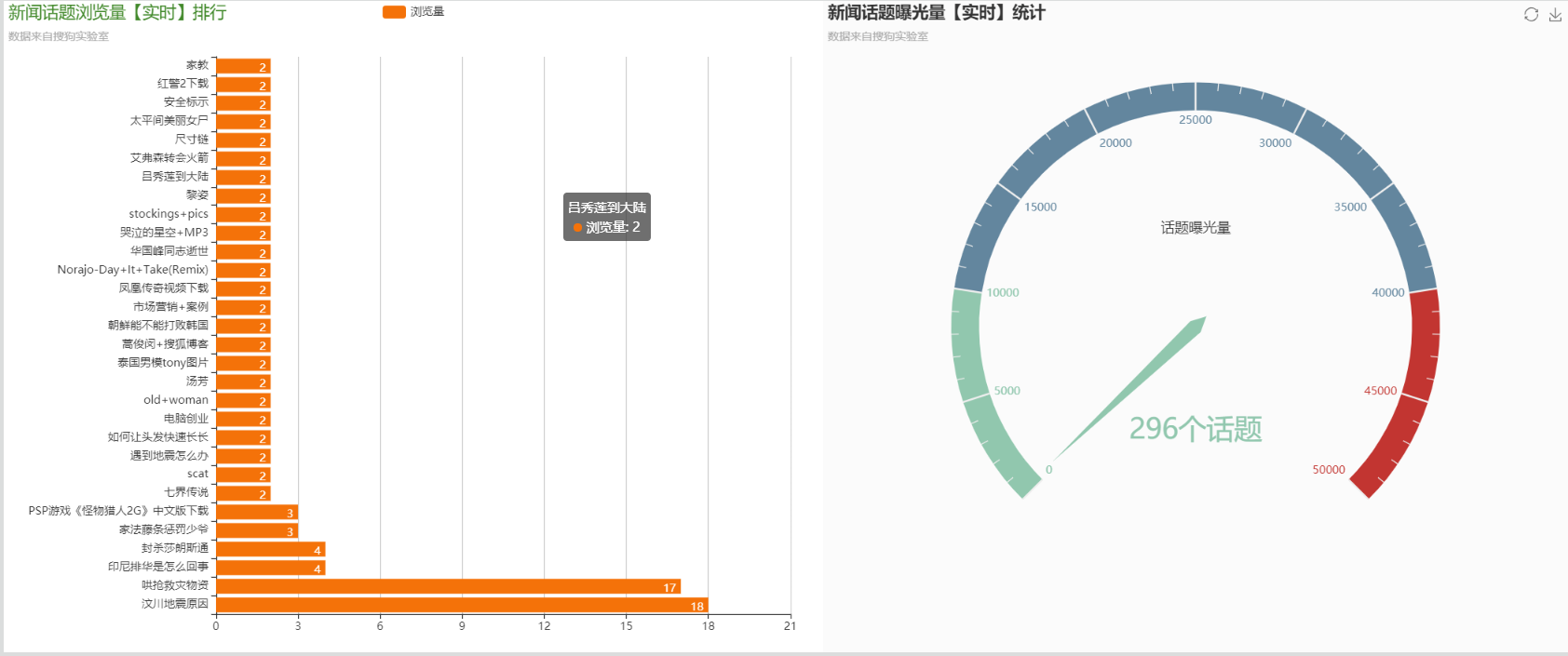
- 实时分析前N名流量最高的新闻话题
- 实时统计当前线上已曝光的新闻话题
- 统计哪个时段用户浏览量最高
- 报表展示
工具、技术、语言
开发工具
- VMware Workstation
- CentOS 6.4
- Xshell 6
- FileZilla
- IntelliJ IDEA 2018
- Notepad++
项目技术点
- zookeeper-3.4.5-cdh5.10.0
- hadoop-2.6.0
- hbase-1.0.0-cdh5.4.0
- spark-2.2.0
- kafka_2.11-0.10.0.0
- flume-1.7.0-bin
- hive-2.1.0
- hue-3.9.0-cdh5.15.0
- mysql
- J2EE
- Websocket
- Echarts
项目语言
- jdk1.8.0_191
- scala-2.11.12
- shell
- maven-3.6.0
架构、数据流程、资源规划
数据流程
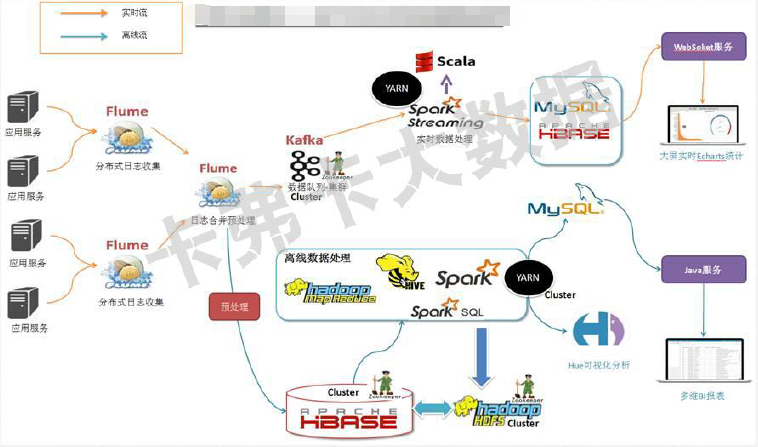
(图片来自于所学课程)
集群资源规划
| bigdata-pro01.bigDAta.com | bigdata-pro02.bigDAta.com | bigdata-pro03.bigDAta.com | |
|---|---|---|---|
| HDFS | NameNode DataNode | NameNode DataNode | DataNode |
| YARN | RescourceManager NodeManager | RescourceManager NodeManager | NodeManager |
| ZooKeeper | ZooKeeper | ZooKeeper | ZooKeeper |
| Kafka | Kafka | Kafka | Kafka |
| HBase | Master RegionServer | Master RegionServer | RegionServer |
| Flume | 日志合并预处理 | 日志采集 | 日志采集 |
| MySQL | MySQL | ||
| Spark | Spark worker | Spark master worker | Spark worker |
| Hive | Hive | ||
| Hue | Hue |
实战
Linux环境准备
总共使用了3台虚拟机,先配置好1台,然后采用VMware Workstation克隆出另外两台,有两台给2G的内存,1台给1G。
常规设置
1)设置ip地址 可以直接使用界面修改ip,如果Linux没有安装操作界面,需要使用命令:vi /etc/sysconfig/network-scripts/ifcfg-eth0来修改ip地址,然后重启网络服务service network restart即可。
2)创建用户
#创建用户命令:
adduser bigDAta
#设置用户密码命令:
passwd bigDAta3)设置主机名 因为Linux系统的主机名默认是localhost,显然不方便后面集群的操作,所以需要手动修改Linux系统的主机名。
#查看主机名命令:
$ hostname
#修改主机名称
$ vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=bigdata-pro01.bigDAta.com4)主机名映射 如果想通过主机名访问Linux系统,还需要配置主机名跟ip地址之间的映射关系。 vi /etc/hosts 192.168.1.151 bigdata-pro01.bigDAta.com 配置完成之后,reboot重启Linux系统即可。 为了能在windows下通过hostname访问Linux系统,也在windows下的hosts文件中配置主机名称与ip之间的映射关系。在windows系统下找到C:\WINDOWS\system32\drivers\etc\路径,打开HOSTS文件添加如下内容: 192.168.1.151 bigdata-pro01.bigDAta.com
5)root用户下设置无密码用户切换 在开发过程中bigDAta用户经常使用root权限操作文件,需要频繁与root用户切换,每次输入密码非常麻烦,故设置无密码切换。修改/etc/sudoers这个文件添加如下代码,即可实现无密码用户切换操作。 vi /etc/sudoers 。。。添加如下内容即可 bigDAta ALL=(root)NOPASSWD:ALL
6)关闭防火墙 我们都知道防火墙对我们的服务器是进行一种保护,但是有时候防火墙也会给我们带来很大的麻烦。 比如它会妨碍hadoop集群间的相互通信,所以我们需要关闭防火墙。
#永久关闭防火墙
vi /etc/sysconfig/selinux
SELINUX=disabled
#查看防火墙状态:
service iptables status
#打开防火墙:
service iptables start
#关闭防火墙:
service iptables stop7)卸载Linux本身自带的jdk 一般情况下jdk需要我们手动安装兼容的版本,此时Linux自带的jdk需要手动删除掉,具体操作如下所示: a)
#查看Linux自带的jdk
rpm -qa|grep java
#删除Linux自带的jdk
rpm -e --nodeps [jdk进程名称1 jdk进程名称2 ...]项目配置
1)bigDAta用户下创建各个目录
#软件目录--未解压的,FileZilla上传
mkdir /opt/softwares
#模块目录--解压的各个框架
mkdir /opt/modules
#工具目录
mkdir /opt/tools
#数据目录
mkdir /opt/datas
#jar
mkdir /opt/jars2)jdk安装(1.8) 大数据平台运行环境依赖JVM,所以我们需要提前安装和配置好jdk。因为安装了64位的centos系统,所以jdk也需要安装64位的,与之相匹配 。
#解压命令
tar -zxf jdk-8u191-linux-x64.tar.gz /opt/modules/
#配置环境变量
vi /etc/profile
export JAVA_HOME=/opt/modules/jdk1.8.0_191
export PATH=$PATH:$JAVA_HOME/bin
#查看是否安装成功
java -version3)克隆虚拟机 在克隆虚拟机之前,需要关闭虚拟机,然后右键选中虚拟机——》管理——》克隆——》下一步——》下一步——》选择创建完整克隆,下一步——》选择克隆虚拟机位置(提前创建好),修改虚拟机名称为Hadoop-Linux-pro-2,然后选择完成即可。 然后使用同样的方式创建第三个虚拟机Hadoop-Linux-pro-3。
4)修改克隆虚拟机配置 对以上配置的常规配置进行相应修改
ZooKeeper分布式集群部署
1)完成ZooKeeper版本下载及安装
2)相关配置
提前创建数据目录/opt/modules/zookeeper-3.4.5-cdh5.10.0/zkData,并在该目录下创建myid文件,编辑每台机器的myid内容为一个整数x,与zoo.cfg文件中server.x对应
<!--zoo.cfg-->
<!--The number of milliseconds of each tick-->
tickTime=2000
<!-- The number of ticks that the initial synchronization phase can take-->
initLimit=10
<!-- The number of ticks that can pass between sending a request and getting an acknowledgement-->
syncLimit=5
<!--the directory where the snapshot is stored. do not use /tmp for storage, /tmp here is just example sakes.-->
dataDir=/opt/modules/zookeeper-3.4.5-cdh5.10.0/zkData
<!-- the port at which the clients will connect-->
clientPort=2181
<!--server.每个节点服务编号 = 服务器ip地址:集群通信端口:选举端口-->
server.1=bigdata-pro01.bigDAta.com:2888:3888
server.2=bigdata-pro02.bigDAta.com:2888:3888
server.3=bigdata-pro03.bigDAta.com:2888:3888Hadoop HA架构与部署
1)完成hadoop版本下载及安装
2)相关配置
非HA Hadoop集群文件参考:点击此链接 https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html 进入,左下角有一个Configuration,点击即可查看相应配置文件;HA Hadoop集群配置,参照此链接 https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
- HDFS相关配置文件
#hadoop-env.sh 运行Hadoop要用到的环境变量
#在默认的基础上添加JAVA_HOME,或者在shell中设置,推荐前者
export JAVA_HOME=/opt/modules/jdk1.8.0_191<!--core-site.xml Hadoop Core 的配置项:HDFS MapReduce YARN常用的I/O设置等-->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>bigDAta</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop-2.6.0/data/tmp</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property>
<!--注意参数一栏不能换行,用逗号隔开即可-->
<property>
<name>ha.zookeeper.quorum</name>
<value>bigdata-pro01.bigDAta.com:2181,bigdata-pro02.bigDAta.com:2181,bigdata-pro03.bigDAta.com:2181</value>
</property>
<property>
<name>hadoop.proxyuser.bigDAta.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.bigDAta.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hue.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hue.groups</name>
<value>*</value>
</property>
</configuration><!--hdfs-site.xml 守护进行的配置项:namenode 辅助namenode datanode -->
<configuration>
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>bigdata-pro01.bigDAta.com:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>bigdata-pro02.bigDAta.com:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>bigdata-pro01.bigDAta.com:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>bigdata-pro02.bigDAta.com:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://bigdata-pro01.bigDAta.com:8485;bigdata-pro02.bigDAta.com:8485;bigdata-pro03.bigDAta.com:8485/ns</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/modules/hadoop-2.6.0/data/jn</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/bigDAta/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--是否开启自动故障转移-->
<property>
<name>dfs.ha.automatic-failover.enabled.ns</name>
<value>true</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
<!--slaves-->
<!--列举了可以运行datanode和节点管理器的机器,这个文件仅有运行在namenode和资源管理器上的控制脚本使用-->
bigdata-pro01.bigDAta.com
bigdata-pro02.bigDAta.com
bigdata-pro03.bigDAta.comHDFS-HA自动故障转移测试
- 启动ZooKeeper集群
- 初始化HA 在ZooKeeper中的状态
bin/hdfs zkfc -formatZK - 启动HDFS服务,注意要提前配置ssh(参考: https://blog.csdn.net/xl132598798/article/details/105513039 ),否则
sbin/start-dfs无法直接启动(第一次启动HDFS服务,需要在namenode进行格式化,bin/hdfs namenode -format) - 在各个namenode节点上启动zkfc线程
sbin/hadoop-daemon.sh start zkfc,先启动zkfc的namenode状态是Active,另一个是Standy - 测试:上传文件到hdfs上,kill状态为Active的namenode,再次查看namenode状态时,就会发现主备切换了
#yarn-env.sh 运行YARN要用到的脚本(覆盖hadoop-env.sh)
if [ "$JAVA_HOME" != "" ]; then
#echo "run java in $JAVA_HOME"
JAVA_HOME=/opt/modules/jdk1.8.0_191
fi
if [ "$JAVA_HOME" = "" ]; then
echo "Error: JAVA_HOME is not set."
exit 1
fi
JAVA=$JAVA_HOME/bin/java
JAVA_HEAP_MAX=-Xmx1000m <!--yarn-site.xml 守护进行的配置项:资源管理器 web应用代理服务器和节点管理器 -->
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>10000</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>rs</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>bigdata-pro01.bigDAta.com</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>bigdata-pro02.bigDAta.com</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>bigdata-pro01.bigDAta.com:2181,bigdata-pro02.bigDAta.com:2181,bigdata-pro03.bigDAta.com:2181</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://bigdata-pro01.bigDAta.com:19888/jobhistory/logs</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>bigdata-pro01.bigDAta.com:8088</value>
</property>
</configuration>YARN-HA故障转移测试
- 在rm1节点上启动yarn服务
sbin/start-yarn.sh - 在rm2节点上启动ResourceManager服务
sbin/yarn-daemon.sh start resourcemanager - 查看yarn的web界面
- 上传文件到hdfs并执行MapReduce例子
- 执行到一半的时候,kill掉rm1上的resourcemanager ,任务会转移到rm2继续处理
#mapred-env.sh 运行MapReduce要用到的脚本(覆盖hadoop-env.sh)
export JAVA_HOME=/opt/modules/jdk1.8.0_191<!--mapred-site.xml 守护进行的配置项:作业历史服务器 -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>bigdata-pro01.bigDAta.com:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>bigdata-pro01.bigDAta.com:19888</value>
</property>
</configuration>HBase分布式集群部署
1)完成HBase版本下载及安装
2)相关配置
#hbase-env.sh
export JAVA_HOME=/opt/modules/jdk1.8.0_191
#使用外部的ZooKeeper
export HBASE_MANAGES_ZK=false<!--hbase-site.xml,需要将hadoop中hdfs-site.xml和core-site.xml拷贝到hbase的conf下,否则启动失败,因为ns配置在hadoop中-->
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://ns/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>bigdata-pro01.bigDAta.com,bigdata-pro02.bigDAta.com,bigdata-pro03.bigDAta.com</value>
</property>
</configuration>3)HBase启动
- 先启动ZooKeeper
- 启动HDFS HA
- 在每个namenode上启动zkfc
- 启动HBase
- 访问web页面查看
4)shell连接
bin/hbase shell进入hbase,创建表CREATE weblogs,info
Kafka分布式集群部署
1)完成Kafka版本下载及安装
2)相关配置
在三台机器上分别配置如下几个文件:
#server.properties
############################# Server Basics #############################
# The id of the broker. This must be set to a unique integer for each broker.
#另外两台机器上分别是1,2
broker.id=0
############################# Socket Server Settings #############################
#修改成为自己机器的ip地址
listeners=PLAINTEXT://bigdata-pro01.bigDAta.com:9092
# The port the socket server listens on
port=9092
# Hostname the broker will bind to. If not set, the server will bind to all interfaces
#修改为自己机器的hostname
host.name=bigdata-pro01.bigDAta.com
# The number of threads handling network requests
num.network.threads=3
# The number of threads doing disk I/O
num.io.threads=8
# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=102400
# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400
# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600
############################# Log Basics #############################
# A comma seperated list of directories under which to store log files
#修改默认的log文件夹
log.dirs=/opt/modules/kafka_2.10-0.9.0.0/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
log.cleaner.enable=false
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=bigdata-pro01.bigDAta.com:2181,bigdata-pro02.bigDAta.com:2181,bigdata-pro03.bigDAta.com:2181
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=6000
配置zookeeper. properties
#该目录需要与zookeeper集群配置保持一致
dataDir=/opt/modules/zookeeper-3.4.5-cdh5.10.0/zkData
# the port at which the clients will connect
clientPort=2181
# disable the per-ip limit on the number of connections since this is a non-production config
maxClientCnxns=0配置producer.properties
metadata.broker.list=bigdata-pro01.bigDAta.com:9092,bigdatapro02.bigDAta.com:9092,bigdata-pro03.bigDAta.com:9092
producer.type=sync
compression.codec=none
# message encoder
serializer.class=kafka.serializer.DefaultEncoder
配置consumer.properties
zookeeper.connect=bigdata-pro01.bigDAta.com:2181,bigdata-pro02.bigDAta.com:2181,bigdata-pro03.bigDAta.com:2181
# timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=6000
#consumer group id
group.id=test-consumer-group3)编写Kafka Consumer执行脚本
#/bin/bash
echo "bigDAta-kafka-consumer.sh start ......"
bin/kafka-console-consumer.sh --zookeeper bigdata-pro01.bigDAta.com:2181,bigdata-pro02.bigDAta.com:2181,bigdata-pro03.bigDAta.com:2181 --from-beginning --topic weblogsFlume数据采集准备
项目使用2台Flume服务器用于日志收集,另一台用于对前2台收集到的日志进行合并及处理,并将数据分发给Kafka、HBase,但是Flume与HBase集成涉及到的表结构是自定义的(需要的参数如下:表名、列簇名),所以由Flume发送至HBase代码需要进行修改,故需要下载flume源码。并在开发工具IDEA中进行修改。
1)完成Flume版本下载及安装
2)源码修改
在IDEA找到解压后的源码包,选中flume-ng-hbase-sink,按照如下方式修改源码,将修改后的flume-ng-hbase-sink源码打成jar包,将原来Flume自带的包覆盖掉即可。
//自定义KfkAsyncHbaseEventSerializer.class,需要与配置文件中agent1.sinks.hbaseSink.serializer的属性值对应
@Override
public List<PutRequest> getActions() {
List<PutRequest> actions = new ArrayList<>();
if (payloadColumn != null) {
byte[] rowKey;
try {
/*---------------------------代码修改开始---------------------------------*/
//解析列字段
String[] columns = new String(this.payloadColumn).split(",");
//解析flume采集过来的每行的值
String[] values = new String(this.payload).split(",");
for(int i=0;i < columns.length;i++) {
byte[] colColumn = columns[i].getBytes();
byte[] colValue = values[i].getBytes(Charsets.UTF_8);
//数据校验:字段和值是否对应
if (colColumn.length != colValue.length) break;
//时间
String datetime = values[0].toString();
//用户id
String userid = values[1].toString();
//根据业务自定义Rowkey
rowKey = SimpleRowKeyGenerator.getKfkRowKey(userid, datetime);
//插入数据
PutRequest putRequest = new PutRequest(table, rowKey, cf,
colColumn, colValue);
actions.add(putRequest);
/*---------------------------代码修改结束---------------------------------*/
}
} catch (Exception e) {
throw new FlumeException("Could not get row key!", e);
}
}
return actions;
}
//根据自己的业务修改这个类中自定义KEY生成的方法
public class SimpleRowKeyGenerator {
public static byte[] getKfkRowKey(String userid,String datetime)throws UnsupportedEncodingException {
return (userid + datetime + String.valueOf(System.currentTimeMillis())).getBytes("UTF8");
}
}3)相关配置
#flume-env.sh
export JAVA_HOME=/opt/modules/jdk1.8.0_191
export HADOOP_HOME=/opt/modules/hadoop-2.6.0
export HBASE_HOME=/opt/modules/hbase-1.0.0-cdh5.4.0主要是对sources、channels、sinks的配置。
Source:source是从一些其他产生数据的应用中接收数据的活跃组件。Source可以监听一个或者多个网络端口,用于接收数据或者可以从本地文件系统读取数据。每个Source必须至少连接一个Channel。基于一些标准,一个Source可以写入几个Channel,复制事件到所有或者某些Channel。
Source可以通过处理器 - 拦截器 - 选择器路由写入多个Channel。
Channel:channel的行为像队列,Source写入到channel,Sink从Channel中读取。多个Source可以安全地写入到相同的Channel,并且多个Sink可以从相同的Channel进行读取。
可是一个Sink只能从一个Channel读取。如果多个Sink从相同的Channel读取,它可以保证只有一个Sink将会从Channel读取一个指定特定的事件。
Flume自带两类Channel:Memory Channel和File Channel。Memory Channel的数据会在JVM或者机器重启后丢失;File Channel不会。
Sink: sink连续轮询各自的Channel来读取和删除事件。
#flume-conf.properties,日志合并及预处理Flume的配置
agent1.sources = r1
agent1.channels = kafkaC hbaseC
agent1.sinks = kafkaSink hbaseSink
agent1.sources.r1.type = avro
agent1.sources.r1.channels = hbaseC kafkaC
agent1.sources.r1.bind = bigdata-pro01.bigDAta.com
agent1.sources.r1.port = 5555
agent1.sources.r1.threads = 5
# flume-hbase
agent1.channels.hbaseC.type = memory
agent1.channels.hbaseC.capacity = 100000
agent1.channels.hbaseC.transactionCapacity = 100000
agent1.channels.hbaseC.keep-alive = 20
agent1.sinks.hbaseSink.type = asynchbase
agent1.sinks.hbaseSink.table = weblogs
agent1.sinks.hbaseSink.columnFamily = info
agent1.sinks.hbaseSink.channel = hbaseC
agent1.sinks.hbaseSink.serializer = org.apache.flume.sink.hbase.KfkAsyncHbaseEventSerializer
agent1.sinks.hbaseSink.serializer.payloadColumn = datatime,userid,searchname,retorder,cliorder,cliurl
#flume-kafka
agent1.channels.kafkaC.type = memory
agent1.channels.kafkaC.capacity = 100000
agent1.channels.kafkaC.transactionCapacity = 100000
agent1.channels.kafkaC.keep-alive = 20
agent1.sinks.kafkaSink.channel = kafkaC
agent1.sinks.kafkaSink.type = org.apache.flume.sink.kafka.KafkaSink
agent1.sinks.kafkaSink.brokerList = bigdata-pro01.bigDAta.com:9092,bigdata-pro02.bigDAta.com:9092,bigdata-pro03.bigDAta.com:9092
agent1.sinks.kafkaSink.topic = weblogs
agent1.sinks.kafkaSink.zookeeperConnect = bigdata-pro01.bigDAta.com:2181,bigdata-pro02.bigDAta.com:2181,bigdata-pro03.bigDAta.com:2181
agent1.sinks.kafkaSink.requiredAcks = 1
agent1.sinks.kafkaSink.batchSize = 1
agent1.sinks.kafkaSink.serializer.class = kafka.serializer.StringEncoder##flume-conf.properties,另2台日志收集服务器的相关配置分别如下:
agent2.sources = r1
agent2.channels = c1
agent2.sinks = k1
agent2.sources.r1.type = exec
agent2.sources.r1.command = tail -F /opt/datas/weblog-flume.log
agent2.sources.r1.channels = c1
agent2.channels.c1.type = memory
agent2.channels.c1.capacity = 10000
agent2.channels.c1.transactionCapacity = 10000
agent2.channels.c1.keep-alive = 5
agent2.sinks.k1.type = avro
agent2.sinks.k1.channel = c1
agent2.sinks.k1.hostname = bigdata-pro01.bigDAta.com
agent2.sinks.k1.port = 5555
agent3.sources = r1
agent3.channels = c1
agent3.sinks = k1
agent3.sources.r1.type = exec
agent3.sources.r1.command = tail -F /opt/datas/weblog-flume.log
agent3.sources.r1.channels = c1
agent3.channels.c1.type = memory
agent3.channels.c1.capacity = 10000
agent3.channels.c1.transactionCapacity = 10000
agent3.channels.c1.keep-alive = 5
agent3.sinks.k1.type = avro
agent3.sinks.k1.channel = c1
agent3.sinks.k1.hostname = bigdata-pro01.bigDAta.com
Flume+HBase+Kafka集成及测试
1)原始日志数据简单处理
- 下载搜狗实验室数据,并在网页上查看格式说明( 数据格式为:访问时间\t用户ID\t[查询词]\t该URL在返回结果中的排名\t用户点击的顺序号\t用户点击的URL 其中,用户ID是根据用户使用浏览器访问搜索引擎时的Cookie信息自动赋值,即同一次使用浏览器输入的不同查询对应同一个用户ID )
- 日志简单处理,将文件中的空格更换为逗号,再次查看格式,发现还有空格存在,再次将空格换成逗号,得到处理后的日志文件weblog.log
2)编写模拟日志生成的过程、
代码实现的功能是将原始日志文件weblog.log,每次读取一行并不断写入另一个文件weblog-flume.log,从而实现日志生成过程。
public class ReadWebLog { private static String readFileName; private static String writeFileName; public static void main(String args[]) { //需要手动收入两个参数 readFileName = args[0]; writeFileName = args[1]; readFile(readFileName); } public static void readFile(String fileName) { try { FileInputStream fis = new FileInputStream(fileName); InputStreamReader isr = new InputStreamReader(fis, "GBK"); //以上两步已经可以从文件中读取到一个字符了,但每次只读取一个字符不能满足大数据的需求。故需使用BufferedReader,它具有缓冲的作用,可以一次读取多个字符 BufferedReader br = new BufferedReader(isr); int count = 0; while (br.readLine() != null) { String line = br.readLine(); count++; // 显示行号 Thread.sleep(300); String str = new String(line.getBytes("UTF8"), "GBK"); System.out.println("row:" + count + ">>>>>>>>" + line); writeFile(writeFileName, line); } isr.close(); } catch (IOException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } }
public static void writeFile(String fileName, String conent) {
try {
FileOutputStream fos = new FileOutputStream(fileName, true);
OutputStreamWriter osw = new OutputStreamWriter(fos);
BufferedWriter bw = new BufferedWriter(osw);
bw.write("\n");
bw.write(conent);
bw.close();
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}}
* 将项目打包成weblogs.jar放在两台日志收集服务器/opt/jars目录下
* 编写运行模拟日志生成的shell脚本weblog-shell.sh
```sh
echo "start log......"
java -jar /opt/jars/weblogs.jar /opt/datas/weblog.log /opt/datas/weblog-flume.log运行./weblog-shell.sh即可不断向weblog-flume.log写入日志信息
编写Flume启动脚本flume-bigDAta-start.sh,第二台的示例如下:
#/bin/bash echo "flume-2 start ......" bin/flume-ng agent --conf conf -f conf/flume-conf.properties -n agent2 -Dflume.root.logger=INFO,console一切正常的话那么接下来就需要,日志合并及处理Flume机器就可以采集到的处理后的数据,接下来是向Kafka分发数据
编写Kafka消费执行脚本,并分发到其他集群内机器上
#/bin/bash echo "bigDAta-kafka-consumer.sh start ......" bin/kafka-console-consumer.sh --zookeeper bigdata-pro01.bigDAta.com:2181,bigdata-pro02.bigDAta.com:2181,bigdata-pro03.bigDAta.com:2181 --from-beginning --topic weblogs
3)数据采集分发测试
启动各个节点上的ZooKeeper
启动HDFS,在每台namenode上,启动zkfc
启动HBase并启动备用master,保证HBase中已有weblogs表
启动Kafka,并创建weblogs topic;
分别启动Flume
在日志收集节点上启动日志模拟生产即weblog-shell.sh
启动编写的Kafka消费脚本,并查看是否一直在进行消费
查看HBase数据库写入情况。
数据采集、处理、分发过程结束,接下来是对数据的分析处理。
离线数据处理
MySQL+Hive
MySQL一方面用来存储Hive的元数据,另一方面存储离线分析的结果。
1)MySQL的安装
2)Hive的安装
#hive-log4j.properties
#日志目录需要提前创建
property.hive.log.dir = /opt/modules/hive-2.1.0/logs
#修改hive-env.sh配置文件
#Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=/opt/modules/hadoop-2.6.0
HBASE_HOME=/opt/modules/hbase-1.0.0-cdh5.4.0
# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/opt/modules/hive-2.1.0/conf
# Folder containing extra ibraries required for hive compilation/execution can be controlled by:
export HIVE_AUX_JARS_PATH=/opt/modules/hive-2.1.0/lib
3)Hive与MySQL集成
- 创建hive-site.xml文件,配置mysql元数据库metastore
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://bigdata-pro01.bigDAta.com/metastore?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!--打印表头-->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<!--打印当前所在数据库-->
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<!--该属性在Hive与HBase集成时用到,Hive通过该属性去连接HBase集群-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>bigdata-pro01.bigDAta.com,bigdata-pro02.bigDAta.com,bigdata-pro03.bigDAta.com</value>
</property>
</configuration>- 在MySQL数据中设置用户连接信息,可以无阻碍访问mysql数据库,其次要保证Hive所在节点能无密钥登录其他集群内节点
4)Hive与MySQL集成测试
- 启动HDFS和YARN服务
- 启动Hive
- 通过Hive服务创建表,并向这个表中加载数据,在Hive查看表中内容
- 在MySQL数据库metastore中查看元数据
Hive+HBase集成
Hive是一个数据仓库,主要是转为MapReduce完成对大量数据的离线分析和决策,之前完成了Flume集成HBase,此时HBase中能源源不断地插入数据,那么如何使Hive中也有数据呢?使用外部表进行Hive与HBase的关联
<!--在hive-site.xml中添加该属性-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>bigdata-pro01.bigDAta.com,bigdata-pro02.bigDAta.com,bigdata-pro03.bigDAta.com</value>
</property>将 HBase中的部分jar包拷贝到Hive中,如果两者都是CDH版本,就不需要进行拷贝;若hive安装时自带了以下jar包,将其删除。使用软连接的方式
export HBASE_HOME=/opt/modules/hbase-1.0.0-cdh5.4.0
export HIVE_HOME=/opt/modules/hive-2.1.0
ln -s $HBASE_HOME/lib/hbase-server-1.0.0-cdh5.4.0.jar $HIVE_HOME/lib/hbase-server-1.0.0-cdh5.4.0.jar
ln -s $HBASE_HOME/lib/hbase-client-1.0.0-cdh5.4.0.jar $HIVE_HOME/lib/hbase-client-1.0.0-cdh5.4.0.jar
ln -s $HBASE_HOME/lib/hbase-protocol-1.0.0-cdh5.4.0.jar $HIVE_HOME/lib/hbase-protocol-1.0.0-cdh5.4.0.jar
ln -s $HBASE_HOME/lib/hbase-it-1.0.0-cdh5.4.0.jar $HIVE_HOME/lib/hbase-it-1.0.0-cdh5.4.0.jar
ln -s $HBASE_HOME/lib/htrace-core-3.0.4.jar $HIVE_HOME/lib/htrace-core-3.0.4.jar
ln -s $HBASE_HOME/lib/hbase-hadoop2-compat-1.0.0-cdh5.4.0.jar $HIVE_HOME/lib/hbase-hadoop2-compat-1.0.0-cdh5.4.0.jar
ln -s $HBASE_HOME/lib/hbase-hadoop-compat-1.0.0-cdh5.4.0.jar $HIVE_HOME/lib/hbase-hadoop-compat-1.0.0-cdh5.4.0.jar
ln -s $HBASE_HOME/lib/high-scale-lib-1.1.1.jar $HIVE_HOME/lib/high-scale-lib-1.1.1.jar
ln -s $HBASE_HOME/lib/hbase-common-1.0.0-cdh5.4.0.jar $HIVE_HOME/lib/hbase-common-1.0.0-cdh5.4.0.jar在Hive中创建一个与HBase中的表建立关联的外部表
create external table weblogs(
id string,
datatime string,
userid string,
searchname string,
retorder string,
cliorder string,
cliurl string
)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES("hbase.columns.mapping" = ":key,info:datatime,info:userid,info:searchname,info:retorder,info:cliorder,info:cliurl")
TBLPROPERTIES("hbase.table.name" = "weblogs");可通过在Hive与HBase中输入count ‘weblogs’,查看数据是否同步。
Cloudera Hue可视化分析
详细过程,记录在 Hue篇中 https://xlxlll.github.io/2020/04/17/Hue/ ,此处仅是流程。
1)下载、安装及编译
2)基本配置
1.配置desktop/conf/hue.ini
2.修改desktop.db文件权限3)集成
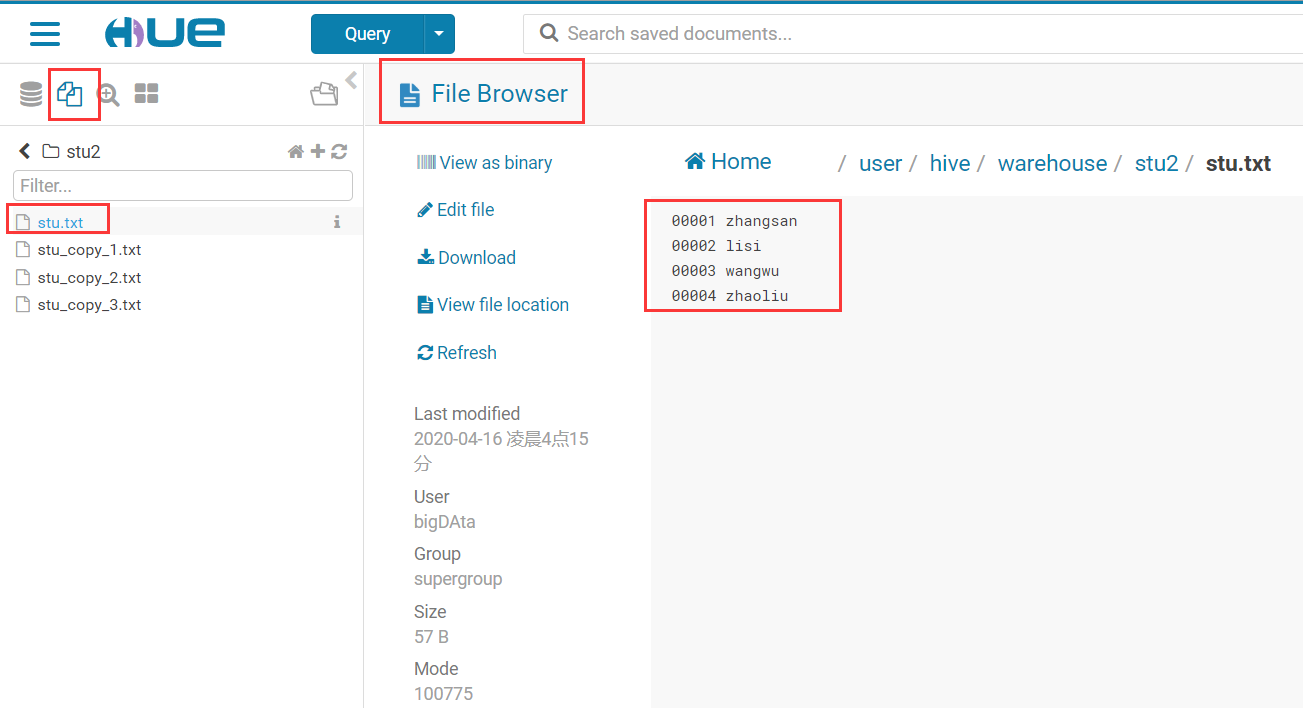
与HDFS集成
与YARN集成
与Hive集成
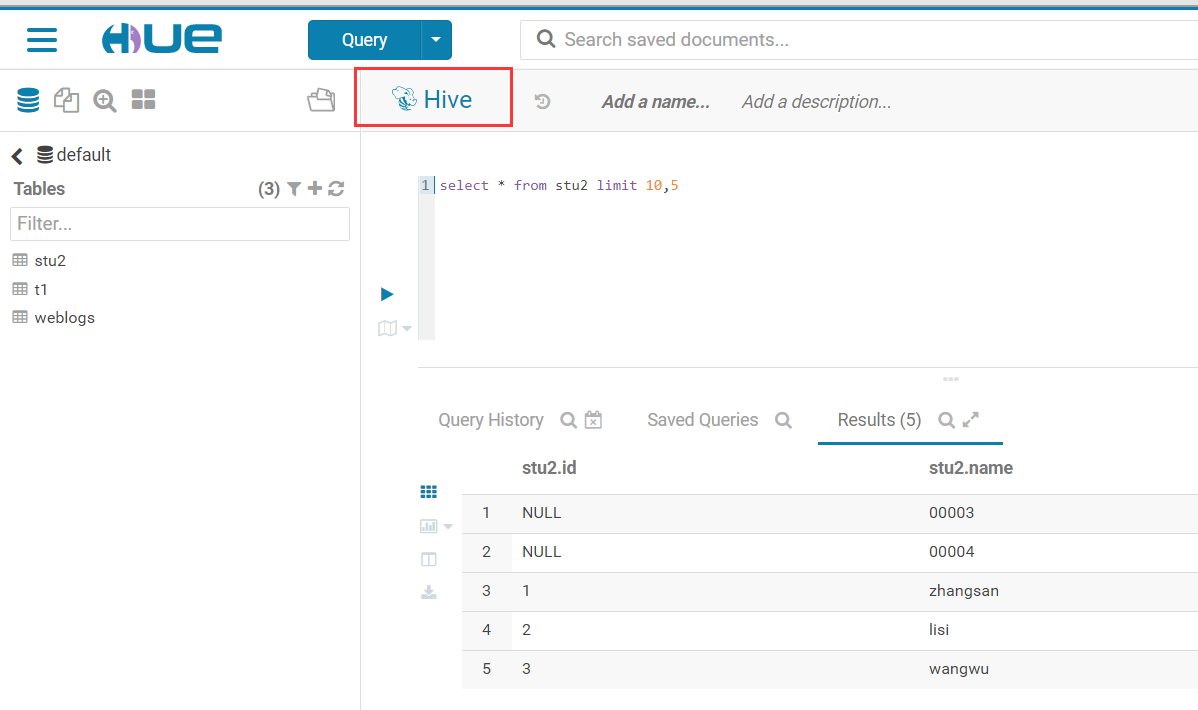
与MySQL集成
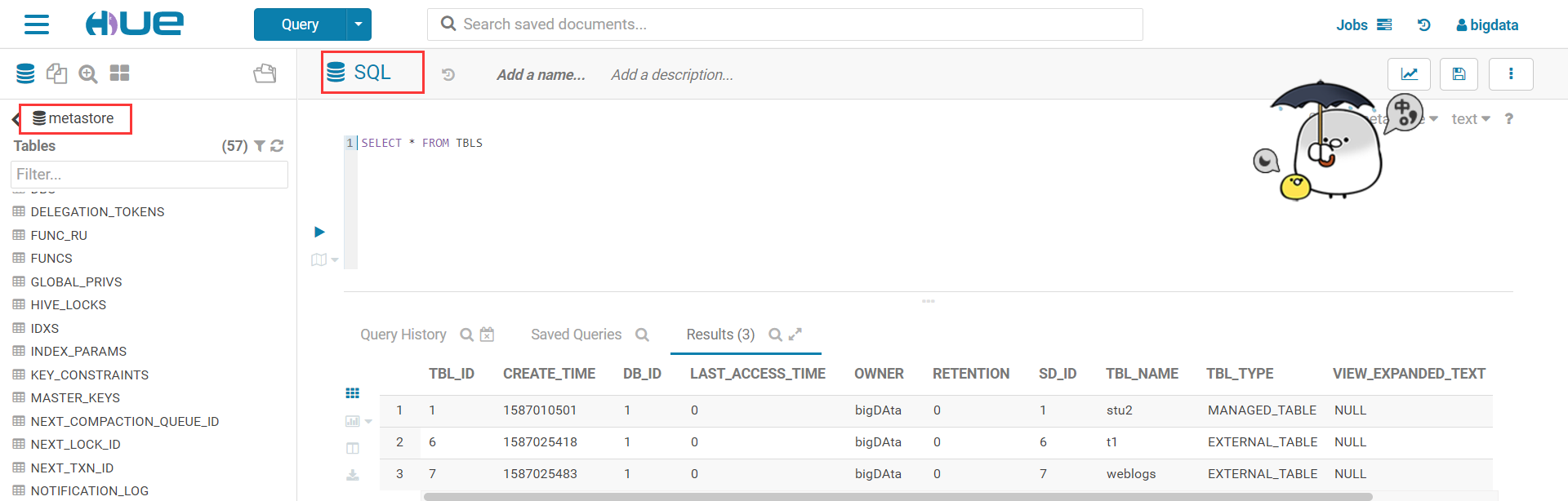
与HBase集成
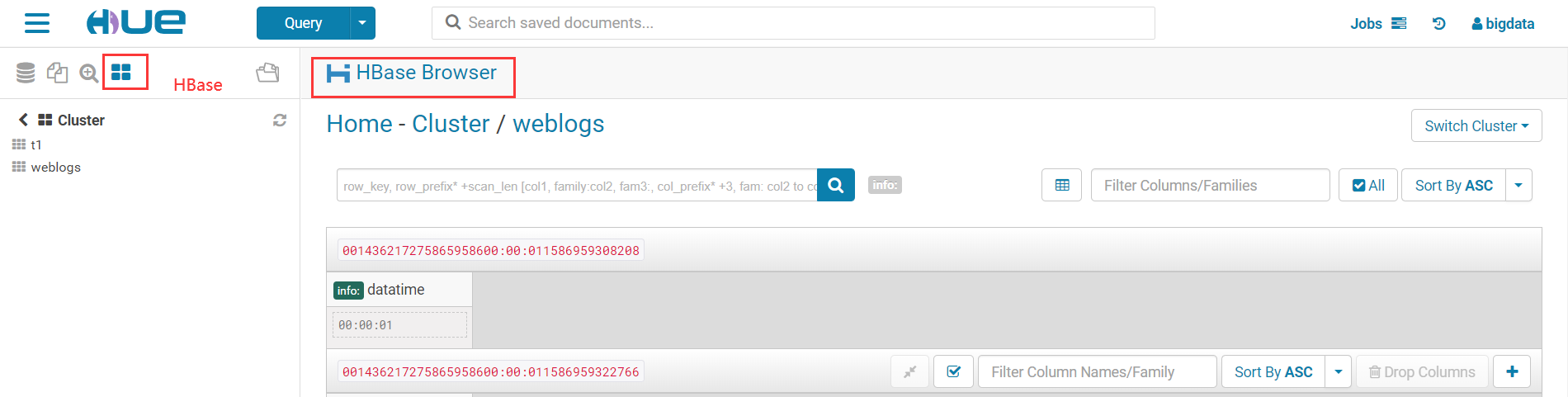
实时数据处理
Spark与Kafka集成
1)Spark下载 安装与编译
具体过程看Spark篇 https://xlxlll.github.io/2020/04/17/Spark/
2)Structured Streaming 与Kafka集成
将
kafka_2.11-0.10.0.0.jar kafka-clients-0.10.0.0.jar spark-sql-kafka-0-10_2.11-2.2.0.jar spark-streaming-kafka-0-10_2.11-2.1.0.jar等包添加到spark下的jars目录下在IDEA中编写如下代码,Structured Streaming从kafka中读取数据,并进行计算
val spark = SparkSession.builder() .master("local[2]") .appName("streaming").getOrCreate() val df = spark .readStream .format("kafka") .option("kafka.bootstrap.servers", "bigdata-pro01.bigDAta.com:9092,bigdata-pro02.bigDAta.com:9092,bigdata-pro03.bigDAta.com:9092") .option("subscribe", "weblogs") .load() import spark.implicits._ val lines = df.selectExpr("CAST(value AS STRING)").as[String] val weblog = lines.map(_.split(",")) .map(x => Weblog(x(0), x(1), x(2),x(3),x(4),x(5))) val titleCount = weblog .groupBy("searchname").count().toDF("titleName","count")
Spark与MySQL集成
由于这里仅仅需要对报表进行展示,前台展示的字段并不多,MySQL完全可以支撑。在HBase中有几百万条数据( 一个浏览话题可能有十几万人搜索过,也就是说一个话题就有十几万条数据,这么大量数据当然要存在Hbase中 ),而经过Spark的计算, 这十几万条数据在mysql中就变成了一条数据(titleName,count)。
如果需要实时查询用户各种信息(数据量很大,字段很多),那么就需要实时的直接从Hbase里查,而不会在Mysql中。
val url ="jdbc:mysql://bigdata-pro01.bigDAta.com:3306/test"
val username="root"
val password="123456"
val writer = new JDBCSink(url,username,password)
val query = titleCount.writeStream
.foreach(writer)
.outputMode("update")
.trigger(ProcessingTime("5 seconds"))
.start()
query.awaitTermination()其中的JDBCSink具体代码如下所示:
import java.sql._
import org.apache.spark.sql.{ForeachWriter, Row}
class JDBCSink(url:String, username:String,password:String) extends ForeachWriter[Row]{
//var是一个变量
//val常量
var statement : Statement =_
var resultSet : ResultSet =_
var connection : Connection=_
override def open(partitionId: Long, version: Long): Boolean = {
connection = new MySqlPool(url,username,password).getJdbcConn();
statement = connection.createStatement()
return true
}
//处理数据
override def process(value: Row): Unit = {
// 将titleName中的[[]]用空格代替。标记一个中括号表达式的开始。要匹配 [,请使用 \[
val titleName = value.getAs[String]("titleName").replaceAll("[\\[\\]]","")
val count = value.getAs[Long]("count");
val querySql = "select 1 from webCount " +
"where titleName = '"+titleName+"'"
val updateSql = "update webCount set " +
"count = "+count+" where titleName = '"+titleName+"'"
val insertSql = "insert into webCount(titleName,count)" +
"values('"+titleName+"',"+count+")"
try{
var resultSet = statement.executeQuery(querySql)
if(resultSet.next()){
//如果有执行updateSql
statement.executeUpdate(updateSql)
}else{
//没有的话就执行insertSql
statement.execute(insertSql)
}
}catch {
case ex: SQLException => {
println("SQLException")
}
case ex: Exception => {
println("Exception")
}
case ex: RuntimeException => {
println("RuntimeException")
}
case ex: Throwable => {
println("Throwable")
}
}
}
override def close(errorOrNull: Throwable): Unit = {
if(statement==null){
statement.close()
}
if(connection==null){
connection.close()
}
}
}而在JDBCSink中用到的MySqlPool连接池的具体代码如下所示
import java.sql.{Connection, DriverManager}
import java.util
class MySqlPool(url:String, user:String, pwd:String) extends Serializable{
private val max = 3 //连接池连接总数
private val connectionNum = 1 //每次产生连接数
private var conNum = 0 //当前连接池已产生的连接数
private val pool = new util.LinkedList[Connection]() //连接池
//获取连接
def getJdbcConn() : Connection = {
//同步代码块
AnyRef.synchronized({
if(pool.isEmpty){
//加载驱动
preGetConn()
for(i <- 1 to connectionNum){
val conn = DriverManager.getConnection(url,user,pwd)
pool.push(conn)
conNum += 1
}
}
pool.poll()
})
}
//释放连接
def releaseConn(conn:Connection): Unit ={
pool.push(conn)
}
//加载驱动
private def preGetConn() : Unit = {
//控制加载
if(conNum < max && !pool.isEmpty){
println("Jdbc Pool has no connection now, please wait a moments!")
Thread.sleep(2000)
preGetConn()
}else{
Class.forName("com.mysql.jdbc.Driver");
}
}
}WEB系统开发
- 从MySQL中查询数据 WeblogService:包括查询20条 titleName,count,以及titleSum
- 基于WebSocket协议的数据推送服务开发
- 基于Echarts框架,编写前端页面的展示index.html
启动各个服务,展示最终结果