[toc]
HDFS、Yarn、MapReduce原理以及执行过程,特别是MapReduce最好能结合源码说一些。
一、HDFS
概述
HDFS(Hadoop Distributed File System,Hadoop分布式文件系统)组件为上层框架提供分布式存储的能力;
是运行在通用硬件(commodity hardware)上,提供流式数据操作、能够处理超大文件的的分布式文件系统,具有高容错性、高吞吐量、容易扩展、高可靠性提供了一个高容错性和高吞吐量的海量数据存储解决方案,且已经成为各大网站等在线服务公司的海量存储事实标准。
体系结构
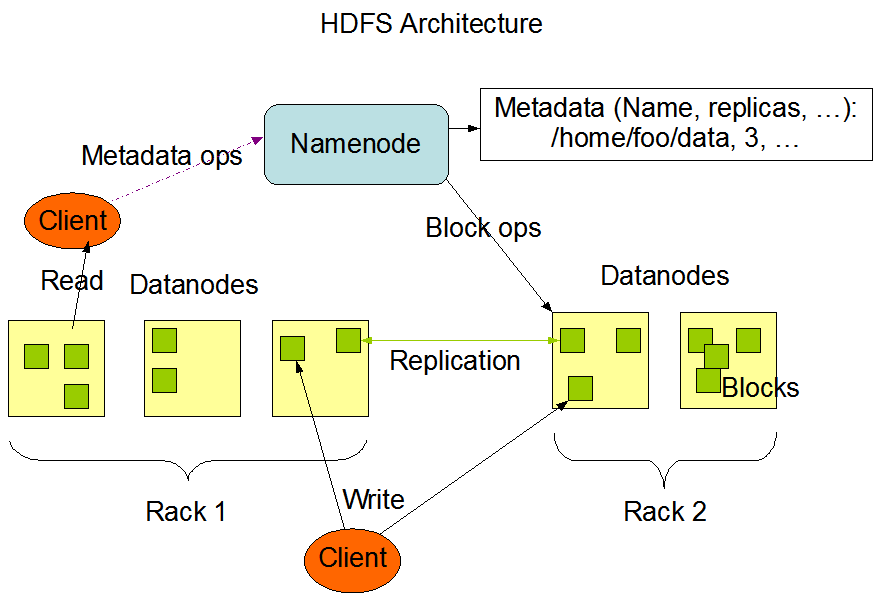
HDFS是一个主/从(Master/Slave)体系结构的分布式系统。HDFS集群拥有一个NameNode(NN)和一些DataNode(DN),其中NameNode是HDFS的Master节点,负责管理文件系统的命令空间(namespace)以及数据块(Block)到具体DataNode节点的映射等信息;DataNode负责管理它所在节点上的存储,如一个文件会被分成一个或者多个数据块,这些块存储在DataNode上,且DataNode会以本地文件的形式保存这些数据块以及数据块的校验信息。
概念
数据块:数据块是HDFS文件处理的最小单元;默认是128MB(1.HDFS文件往往较大,2.最小化寻址开销),数据块会以文件的形式存储在DN的磁盘上;因为一个数据块冗余备份到不同的DN上(默认是3分),所以一个副本的丢失并不会影响这个数据块的访问;
名字节点(NameNode):
NN管理这文件系统的命名空间,包括文件系统目录树、文件/目录信息以及文件的数据块索引,这些信息以命名空间镜像文件和编辑日志文件的形式永久保存在NN的本地磁盘上。NN还保存Block与DN的对应关系,这些数据是NN启动时动态构建的,并不保存在NN的本地磁盘上。
为解决NN的单点问题,引入名字节点高可用性(HA),一个HA集群中有2个NN—1个活动NN(Active)和一个备用NN(StandBy)。
如果集群中文件数量过多,NN的内存将成为限制系统横向扩展的瓶颈。引入
联邦HDFS机制(HDFS Federation)解决这一问题。数据节点(Datanode):将新的数据块写入本地存储,读出本地存储上的数据块;作为从节点,不断向NN发送心跳、数据块汇报以及缓存汇报,NN通过心跳、数据块汇报以及缓存汇报的响应向DN发送指令。
客户端:提供了多种客户端接口,均是建立在DFSClient类的基础之上,
HDFS通信协议:为降低节点间代码的耦合性,提高单个节点代码的内聚性,HDFS将这些节点间的调用抽象成不同的接口:Hadoop RPC,基于TCP/HTTP实现的流式接口。
HDFS通信协议
Hadoop RPC :
基于Protobuf实现,主要定义在org.apache.hadoop.hdfs.protocol包和org.apache.hadoop.hdfs.server.protocol包中。包括以下几个接口。
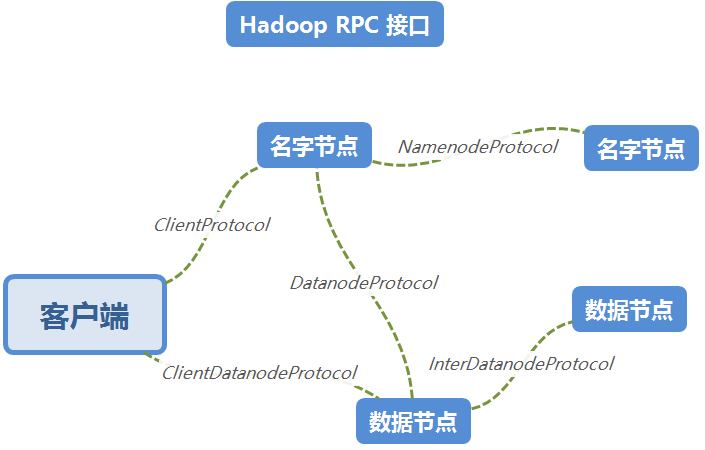
ClientProticol
——定义了所有由客户端发起、Namenode响应的操作。客户端对文件系统的所有操作都是通过这个接口。主要有以下几类:
HDFS文件读相关的操作
//获取HDFS文件指定范围内所有数据块的位置信息 getBlockLocations() reportBadBlocks()
HDFS文件写以及追加相关的操作
管理HDFS命名空间(namespace)的相关操作
系统问题与管理相关操作
快照相关操作
缓存相关操作
- 其他操作
ClientDatanodeProtocol
——定义了客户端与DN间的接口,主要是用于客户啊短获取DN信息时调用,真正的数据读写交互式通过流式接口进行的;
DatanodeProtocol
——定义了DN与NN之间的接口(双向,是DN与NN通信的唯一方式);
InterDatanodeProtocol
——DN与DN间的接口,主要用于Block的恢复、以及同步DN上存储的副本信息
NamenodeProtocol
——第二NN与NN间的接口;
其他接口——安全相关、HA相关
组件、概念、经典的流程,各个组件间RPC接口的定义
流式接口
RPC框架实现
设计模式、编程模型、语言技巧
NameNode实现
Namenode HA、元数据的管理,
DataNode实现
Federation NameNode
HDFS客户端实现
为什么只对namenode进行初始化,因为namenode管理所有文件系统的元数据,而datanode可以动态加入或离开集群,所以初始化不涉及datanode;通过创建存储目录和初始版本的namenode持久数据结构,格式化将创建一个空的文件系统。不需要指定文件系统的大小,这是由datanode的数量决定的,可以在格式化之后根据需求增加。
#格式化
bin/hdfs namenode -format
#默认情况下该命令从fs.defaultFS中找到namenode的主机名
hdfs getconf -namenodes
#在每台机器上启动一个namenode,通过hdfs getconf -namenodes得到的返回值确定,在slaves文件列举的每台机器上启动一个datanode,每台机器上启动一个辅助namenode,由hdfs getconf -secondarynamenodes得到的返回值确定
sbin/start-dfs.sh#在本地机器上启动一个资源管理器,在slaves文件列举的每台机器上启动一个节点管理器
start-yarn.sh
#作业历史服务器
mr-jobhistory-daemon.sh start historyserver一旦运行Hadoop集群,就需要给用户提供访问手段,为每个用户创建home目录,给目录设置用户访问许可
#hadoop fs不只应用于hdfs文件系统,可以用于其他文件系统
hadoop fs -mkdir /user/username
hadoop fs -chown username:username /user/username
#hadoop dfs 针对hdfs分布式文件系统,已过时
#hdfs dfs 作用相同,推荐使用为什么集群下不适合一体适用的配置模型:当添加新的机器时,新机器的硬件规格与现有机器不同时,需要新建一套文件
日志文件的类型:
.log通过log4j记录:日常滚动文件追加方式循环管理日志文件,不自动删除过期的日志文件
.out记录标准输出和标准错误日志
对于一个正在运行的守护进程,要想知道其实际配置,访问该进程web服务器上的/conf页面
基础知识
- Java NIO
- 动态代理
- protobuf
二、MapReduce
MapReduce组件为上层框架提供分布式计算的能力;
MapReduce流程
map端
- 由InputFormat类(默认是TextInputFormat)来读取外部文件,它会调用RecordReader的read()方法来读取,返回K,V键值对;
- 将K,V键值对传送给map()方法,作为其入参来执行用户定义的map逻辑
- context.write()
reduce端
shuffle
shuffle的理解:
https://blog.csdn.net/u014374284/article/details/49205885
三、YARN
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>10000</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>rs</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>bigdata-pro01.bigDAta.com</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>bigdata-pro02.bigDAta.com</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>bigdata-pro01.bigDAta.com:2181,bigdata-pro02.bigDAta.com:2181,bigdata-pro03.bigDAta.com:2181</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://bigdata-pro01.bigDAta.com:19888/jobhistory/logs</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>bigdata-pro01.bigDAta.com:8088</value>
</property>四、Hadoop源码环境搭建
出现的问题
1.HDFS集群无法启动DataNode节点
问题描述:
执行./start-dfs.sh之后,使用jps查询进程时,发现dataNode并未启动;执行./stop-dfs.sh之后,返现:no datanode to stop
分析过程:
当使用hdfs namenode -format格式化namenode时,会重新生成集群的相关信息,特别是clusterID,每次刷新都会产生一个新 的clusterID;但是该操作却不会影响DataNode节点的集群信息;
会在namenode数据文件夹中保存一个current/VERSION文件,记录clusterID,而datanode中保存的current/VERSION文件中的clusterID的值是第一次格式化保存的clusterID,这样导致datanode和namenode之间的ID不一致,从而出现问题;
解决过程:
查看
hdfs-site.xml文件获取Hadoop数据存储的位置,分别找到…/dfs/name/current,…/dfs/data/current目录下的VERSION文件,查看NameNode和DataNode节点的clusterID- 修改namenode与datanode的clusterID的值;
- 停止HDFS集群后,同时删除NameNode和DataNode节点中配置的存储Hadoop数据的文件目录的所有子目录及文件;
再次使用
hdfs namenode -format命令格式化NameNode节点,重启HDFS集群。执行格式化过程中出现如下提示:
Call From bigdata-pro01.bigDAta.com/192.168.1.151 to bigdata-pro01.bigDAta.com:8485 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused at org.apache.hadoop.hdfs.qjournal.client.QuorumException.create(QuorumException.java:81) at org.apache.hadoop.hdfs.qjournal.client.QuorumCall.rethrowException(QuorumCall.java:223) at org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager.hasSomeData(QuorumJournalManager.java:232) at org.apache.hadoop.hdfs.server.common.Storage.confirmFormat(Storage.java:884) at org.apache.hadoop.hdfs.server.namenode.FSImage.confirmFormat(FSImage.java:171) at org.apache.hadoop.hdfs.server.namenode.NameNode.format(NameNode.java:937) at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1379) at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1504)解决过程:
执行
[bigDAta@bigdata-pro01 hadoop-2.6.0]$ ./sbin/hadoop-daemon start journalnode命令,在次执行格式化命令。在修复过程中出现namenode无法启动:
Directory /opt/modules/hadoop-2.6.0/data/tmp/dfs/name is in an inconsistent state: storage directory does not exist or is not accessible.重新进行
namenode格式化
Could not locate executable D:\ideaWorkSpce\bigData_software\hadoop-2.6.0\bin\winutils.exe in the Hadoop binaries.
<!--缺少winutils.exe文件-->


