[toc]
分布式架构
集中式
概述:集中式系统就是指由一台或多台计算机组成中心节点,数据集中存储于这个中心节点,并且整个系统的所有业务单元都集中部署在这个中心节点上,系统的所有功能均由其集中处理。
特点:部署结构简单,容易出现单点问题。
分布式
概述:分布式系统是一个硬件或软件组件分布在不同的网络计算机上,彼此之间仅仅通过消息传递进行通信和协调的系统。
特点:
分布性:分布式系统中的多台计算机都会在空间上随意分布,同时,机器的分布情况也会随时变动
对等性:分布式系统中的计算机没有主/从之分,组成分布式系统的所有计算机节点都是对等的。在分布式系统中,为了对外提供高可用的服务,常常会对数据和服务进行副本处理。
并发性:
缺乏全局时钟:
故障总是会发生:任何在设计阶段考虑到的异常情况,一定会在系统实际运行中发生,并且,在系统实际运行过程中还会遇到很多在设计时未考虑到的异常故障。
分布式环境的各种问题:
通信异常、网络分区(网络发生异常,导致在分布式系统中的所有节点中,只有部分节点之间能够进行正常通信,而另一些节点则不能,俗称脑裂)、三态(成功、失败、超时)、节点故障(组成分布式系统的服务器节点出现的宕机或僵死现象)
从ACID到CAP/BASE
ACID
事务(Transaction)是由一系列对系统中数据进行访问与更新的操作所组成的一个程序执行逻辑单元。
(1) Atomic(原子性)
事务必须是一个原子的操作序列单元,事务中包含的各项操作在一次执行过程中,要么全部执行成功,要么全部不执行,任何一项失败,整个事务回滚,只有全部都执行成功,整个事务才算成功。
(2) Consistency(一致性)
事务的执行不能破坏数据库数据的完整性和一致性,事务在执行之前和之后,数据库都必须处于一致性状态。
(3) Isolation(隔离性)
在并发环境中,并发的事务是相互隔离的,一个事务的执行不能被其他事务干扰。即不同的事务并发操纵相同的数据时,每个事务都有各自完整的数据空间,即一个事务内部的操作及使用的数据对其他并发事务是隔离的,并发执行的各个事务之间不能相互干扰。
(4) 4. Durability(持久性)
一个事务一旦提交,它对数据库中对应数据的状态变更就应该是永久性的,即使发生系统崩溃或机器宕机,只要数据库能够重新启动,那么一定能够将其恢复到事务成功结束时的状态。
四种隔离级别
(1) 读未提交
允许脏读。如果一个事务正在处理某一数据,并对其进行了更新,但同时尚未完成事务,因此事务没有提交,与此同时,允许另一个事务也能够访问该数据。例如A将变量n从0累加到10才提交事务,此时B可能读到n变量从0到10之间的所有中间值。
(2) 读已提交
允许不可重复读。只允许读到已经提交的数据。即事务A在将n从0累加到10的过程中,B无法看到n的中间值,之中只能看到10。同时有事务C进行从10到20的累加,此时B在同一个事务内再次读时,读到的是20。
(3) 可重复读
允许幻读。保证在事务处理过程中,多次读取同一个数据时,其值都和事务开始时刻时是一致的。禁止脏读、不可重复读。幻读即同样的事务操作,在前后两个时间段内执行对同一个数据项的读取,可能出现不一致的结果。保证B在同一个事务内,多次读取n的值,读到的都是初始值0。幻读,就是不同事务,读到的n的数据可能是0,可能10,可能是20
(4) 串行化
最严格的事务,要求所有事务被串行执行,不能并发执行。
如果不对事务进行并发控制,我们看看数据库并发操作是会有那些异常情形
- 一类丢失更新:两个事物读同一数据,一个修改字段1,一个修改字段2,后提交的恢复了先提交修改的字段。
- 二类丢失更新:两个事物读同一数据,都修改同一字段,后提交的覆盖了先提交的修改。
- 脏读:读到了未提交的值,万一该事物回滚,则产生脏读。
- 不可重复读:两个查询之间,被另外一个事务修改了数据的内容,产生内容的不一致。
- 幻读:两个查询之间,被另外一个事务插入或删除了记录,产生结果集的不一致。
CAP
分布式事务是指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于分布式系统的不同节点之上。
CAP理论:一个分布式系统不可能同时满足C(一致性)、A(可用性)、P(分区容错性)这三个基本需求,最多同时满足其中的两项:
(1) 一致性
分布式环境中,一致性是指多个副本之间能否保持一致的特性。在一致性的需求下,当一个系统在数据一致的状态下执行更新操作后,应该保证系统的数据仍然处理一致的状态。
(2) 可用性
系统提供的服务必须一直处于可用的状态,对于用户的每一个操作请求总是能够在有限的时间内返回结果。
- 有限时间内:对于用户的一个操作请求,系统必须能够在指定的时间(响应时间)内返回对应的处理结果,如果超过了这个时间范围,那么系统就被认为是不可用的。即这个响应时间必须在一个合理的值内,不让用户感到失望。
- 返回正常结果:要求系统在完成对用户请求的处理后,返回一个正常的响应结果。正常的响应结果通常能够明确地反映出对请求的处理结果,即成功或失败,而不是一个让用户感到困惑的返回结果。比如返回一个系统错误如 OutOfMemory,则认为系统是不可用的。
(3) 分区容错性
即分布式系统在遇到任何网络分区故障时,仍然需要能够保证对外提供满足一致性和可用性的服务,除非是整个网络环境都发生了故障。
网络分区,是指分布式系统中,不同的节点分布在不同的子网络(机房/异地网络)中,由于一些特殊的原因导致这些子网络之间出现网络不连通的状态,但各个子网络的内部网络是正常的,从而导致整个系统的网络环境被切分成了若干孤立的区域。组成一个分布式系统的每个节点的加入与退出都可以看做是一个特殊的网络分区。
CAP应用
- 放弃 P:放弃分区容错性的话,则放弃了分布式,放弃了系统的可扩展性
- 放弃 A:放弃可用性的话,则在遇到网络分区或其他故障时,受影响的服务需要等待一定的时间,再此期间无法对外提供政策的服务,即不可用
- 放弃 C:放弃一致性的话(这里指强一致),则系统无法保证数据保持实时的一致性,在数据达到最终一致性时,有个时间窗口,在时间窗口内,数据是不一致的。
对于分布式系统来说,P 是不能放弃的,因此架构师通常是在可用性和一致性之间权衡。
BASE
Basically Available(基本可用)、Soft state(软状态)、Eventually consistent(最终一致性),基于 CAP 定理演化而来,核心思想是即时无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。
(1) Basically Available(基本可用)
基本可用是指分布式系统在出现不可预知的故障的时候,允许损失部分可用性,但不等于系统不可用。
- 响应时间上的损失:当出现故障时,响应时间增加
- 功能上的损失:当流量高峰期时,屏蔽一些功能的使用以保证系统稳定性(服务降级)
(2) Soft state(软状态)
与硬状态相对,即是指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时。
(3) Eventually consistent(最终一致性)
强调系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。其本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
最终一致性可分为如下几种:
因果一致性(Causal consistency)即进程 A 在更新完数据后通知进程 B,那么之后进程 B 对该项数据的范围都是进程 A 更新后的最新值。读己之所写(Read your writes)进程 A 更新一项数据后,它自己总是能访问到自己更新过的最新值。会话一致性(Session consistency)将数据一致性框定在会话当中,在一个会话当中实现读己之所写的一致性。即执行更新后,客户端在同一个会话中始终能读到该项数据的最新值单调读一致性(Monotonic read consistency)如果一个进程从系统中读取出一个数据项的某个值后,那么系统对于该进程后续的任何数据访问都不应该返回更旧的值。单调写一致性(Monotoic write consistency)一个系统需要保证来自同一个进程的写操作被顺序执行。
BASE 定理是提出通过牺牲一致性来获得可用性,并允许数据在一段时间内是不一致的,但最终达到一致状态。
ZAB协议
ZAB协议:ZooKeeper原子消息广播协议,实现一种主备模式框架下保持集群中各个副本之间的数据统一性。
消息广播:Leader服务器将每个事务请求生成对应的proposal,并为这个proposal分配一个全局单调递增的唯一ID(ZXID),Leader服务器与每个follower之间都有一个队列,Leader将消息发送到该队列,将proposal广播给所有的Follower服务器,Follower服务器以事务日志的形式写入磁盘,成功写入之后反馈给Leader服务器一个ACK相应,当Leader接收超过半数的ACK后,开始广播commit消息,同时Leader自身完成对事务的提交,每一个Follower服务器接收到commit消息后也完成对事务的提交;
崩溃恢复:当Leader服务器出现故障后,就会进入崩溃恢复模式。崩溃恢复模式的要求:(1)确认已经被Leader提交的proposal必须被所有的Follower服务器提交;(2)确认丢弃已经被Leader提出的但没有被提交的proposal。优先选择拥有最大ZXID的proposal的服务器作为Leader,以满足上述要求,之后进行数据同步。
数据同步:Leader会将自身的提交的最大proposal的事务ZXID发送给其他的follower节点。follower节点根据Leader的消息进行回退或者数据同步操作。最终目的要保证集群中所有节点的数据副本保持一致。
ZAB协议原理:
每个Leader都需要经历:发现、同步、广播
- 发现:ZooKeeper集群必须选择出一个Leader进程,同时Leader进程维护一个follower可用列表,客户端和follower列表中的节点进行通信;
- 同步:Leader要负责将自身的数据与follower进行同步,做到多副本存储;
- 广播:Leader接受客户端新的proposal请求,将新的proposal请求广播给所有的follower。
系统模型
版本——保证分布式数据原子性操作
对数据节点的任何更新操作都会引起版本号的变化,ZooKeeper中的版本号是对数据节点的数据内容、子节点列表或节点ACL信息的修改次数(即使两次修改并没有使得数据内容的值发生变化,version的值依旧会变更)。
| 版本类型 | 说明 |
|---|---|
| version | 当前数据节点数据内容的版本号 |
| cversion | 当前数据节点子节点的版本号 |
| aversion | 当前数据节点ACL变更版本号 |
在并发环境下,需要通过一些机制来保证这些数据在某个操作过程中不会被外界修改,这样的机制就称为“锁”。
悲观锁:又称悲观并发控制(Pessimistic Concurrency Control,PCC),有效避免不同事务对同一数据并发更新而造成的数据一致性问题。如果事务A正在对数据进行处理,那么整个处理过程中,都会将数据处于锁定状态,直到事务A完成对该数据的处理,释放了对应的锁之后,其他事务才能重新竞争对该数据进行更新操作。悲观锁假定不同事务之间的处理一定会出现相互干扰,从而需要在一个事务从头到尾的过程中都对数据进行加锁处理。
乐观锁:又称乐观并发控制(Optimistic Concurrency Control,OCC),乐观锁假定多个事务在处理过程中不会彼此影响,因此在事务处理的绝大部分时间里不需要进行加锁处理。在更新请求提交之前,每个事务都会首先检查当前事务读取数据后,是否有其他事务对该数据进行了修改,如果其他事务有更新,那么正在提交的事务就需要回滚。可以看出乐观锁主要分为数据读取、写入校验、数据写入,关键在于写入校验,如何确保数据一致性?
CAS:对于值V,每次更新前都会对比其值是否是预期值A,只有符合预期,才会将V原子化地更新到新值B(比如想修改一个值,当前值为0,先读取当前值E=0,计算修改之后的值P=1,在将1写回时,再次读取当前值N,若N = E,则认为没有线程修改过该值,若N!=E,认为有线程修改过,则读取当前值N为E,循环之前的过程)。—这是一种不加锁的
其中是否符合预期便是乐观锁中的“写入校验”阶段。
Watcher——数据变更的通知
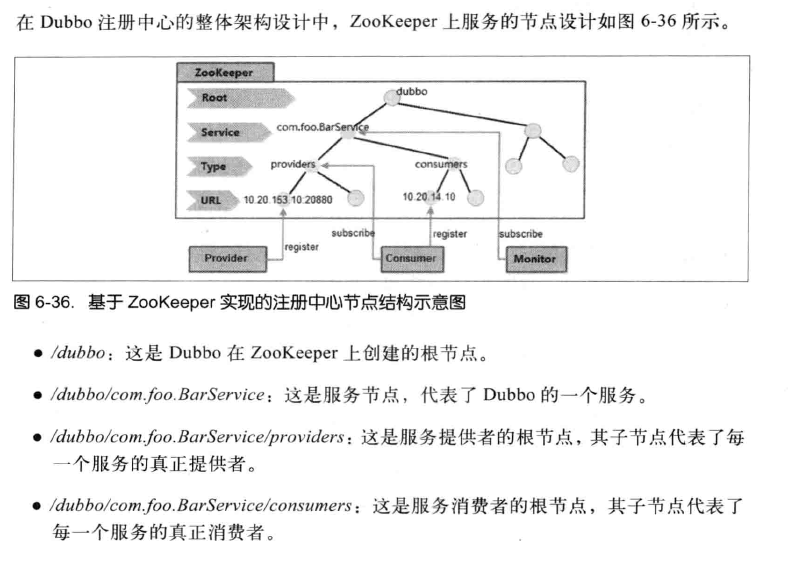
服务提供者:服务提供者在初始化启动时,会在ZooKeeper的/dubbo/com.foo.BarService/providers节点下创建一个子节点,并写入自己的URL地址,这就代表了com.foo.BarService服务的一个提供者;
服务消费者:服务消费者在启动时,读取并订阅ZooKeeper上/dubbo/com.foo.BarService/providers节点下的所有子节点,并解析出所有提供者的URL地址作为该服务地址列表,然后发起正常调用;同时会在ZooKeeper的/dubbo/com.foo.BarService/consumers节点下创建一个子节点,并写入自己的URL地址,这就代表了com.foo.BarService服务的一个消费者;
监控中心:监控中心会在启动时,通过ZooKeeper的/dubbo/com.foo.BarService节点来获取所有提供者和消费者的URL地址,并注册Watcher来监听其子节点变化。
所有提供者、消费者在ZooKeeper上创建的节点都是临时节点,利用的是临时节点的生命周期和客户端会话相关的特性,一旦客户端出现故障,临时节点就会自动从ZooKeeper上删除。而/dubbo/com.foo.BarService这样的服务节点是持久化节点。
问题:
问题描述:
启动Hmaster之后一段时间,就会自动关闭。
zookeeper.MetaTableLocator: Failed verification of hbase:meta,,1 at address=bigdata-pro01.bigDAta.com,60020,1586616
507310, exception=org.apache.hadoop.hbase.NotServingRegionException: Region hbase:meta,,1 is not online on bigdata-pro01.bigDAta.com,60020,1586617997438
at org.apache.hadoop.hbase.regionserver.HRegionServer.getRegionByEncodedName(HRegionServer.java:2791)
at org.apache.hadoop.hbase.regionserver.RSRpcServices.getRegion(RSRpcServices.java:886)
at org.apache.hadoop.hbase.regionserver.RSRpcServices.getRegionInfo(RSRpcServices.java:1168)
at org.apache.hadoop.hbase.protobuf.generated.AdminProtos$AdminService$2.callBlockingMethod(AdminProtos.java:20862)
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:2035)
at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:107)
at org.apache.hadoop.hbase.ipc.RpcExecutor.consumerLoop(RpcExecutor.java:130)
at org.apache.hadoop.hbase.ipc.RpcExecutor$1.run(RpcExecutor.java:107)
at java.lang.Thread.run(Thread.java:748)
格式化HDFS后,因为zookeeper中某些遗留文件导致的,删除自定义dataDir目录下的除myid之外的所有文件,重新运行即可解决。



